
|
|
Программирование >> Синтаксис инициирования исключений
CMP<Type> operator->() { return *pointee; } Если использовать дескрипторы в сочетании с ведущими указателями, можно выбрать, для каких экземпляров класса следует подсчитывать ссылки, а какие экземпляры должны управляться другим способом. Трудности подсчета ссылок Все выглядит так просто; однако без ложки дегтя дело все же не обходится. Подсчет ссылок обладает одним очень распространенным недостатком - зацикливанием. Представьте себе ситуацию: объект А захватил объект В (то есть вызвал для него функцию Grab()), а объект В сделал то же самое для объекта А. Ни на А, ни на В другие объекты не ссылаются. Здравый смысл подсказывает, что А следует удалить вместе с В, но они продолжают существовать, поскольку их счетчики ссылок так и не обнуляются. Обидно, да? Подобное зацикливание возникает сплошь и рядом. Оно может относиться не только к парам объектов, но и целым подграфам. A -> B -> C -> D -> A, но никто за пределами этой группы не ссылается ни на один из этих объектов. Группа словно плывет на Летучем Голландце , построенном в эпоху высоких технологий и обреченном на вечные скитания в памяти. Существует несколько стратегий борьбы с зацикливаниями. Все они не обладают особой универсальностью, и в вашей конкретной ситуации это может привести к отказу от подсчета ссылок. Как правило, встречаясь с проблемой циклических ссылок, стоит рассмотреть более хитроумные приемы, описанные в двух последних главах. Как видите, мысль об отказе от подсчета ссылок приходит довольно быстро. Декомпозиция Предположим, А захватывает В, а затем В захватывает некоторый компонент А: class A { private: Foo* foo; B* b; Если сделать так, чтобы В выполнял захват в функции foo, проблем не возникает. Когда последняя ссылка на A ликвидируется, его счетчик становится равным 0, поскольку В его не увеличивает. Для этого придется проявить некоторую изрядную изобретательность при кодировании, к тому же дизайн сильно зависит от особенностей конкретных объектов, но на удивление часто он решает проблему зацикливания. Сильные и слабые дескрипторы Предположим, ссылка А на В создавалась через Grab(), а ссылка В на А - нет. В тот момент, когда исчезнет последняя ссылка на А из внешнего мира, подсчет ссылок для обоих объектов пары прекратит их существование. На этой идее основано различие между силънгми (strong) и слабыми (weak) дескрипторами или указателями с подсчетом ссылок. Описанный выше шаблон CH будет относиться к сильным дескрипторам, поскольку поддерживает счетчик ссылок. Обычный шаблон дескриптора (без вызова Grab и Release) будет относиться к слабым. Если спроектировать архитектуру объектов так, чтобы не существовало циклических подграфов, содержащих исключительно сильные дескрипторы, то вся схема подсчета ссылок снова возвращается в игру. Самая распространенная ситуация с таким решением - иерархия целое/часть, в которой пары удаляются при удалении целого. Целые поддерживают сильные ссылки, части - слабые. Подсчет ссылок и ведущие указатели Одно из самых распространенных и полезных применений подсчета ссылок заключается в управлении ведущими указателями. В предыдущих главах эта тема упоминалась неоднократно. Дескрипторы живут в стеке и потому автоматически уничтожаются при сборке мусора, выполняемой компилятором. Однако ведущие указатели (по тем же причинам, что и объекты) обычно приходится создавать в куче. Как узнать, когда следует удалять ведущий указатель? Подсчет ссылок упрощает эту задачу. Проблем с зацикливанием не будет: поскольку ведущий указатель не хранит ссылок на свои дескрипторы, связь является односторонней. Копируемые и передаваемые дескрипторы сохраняют длину в четыре байта без виртуальных функций, а лишь тривиальными подставляемыми функциями. Grab и Release съедают несколько дополнительных машинных тактов, но это мелочи по сравнению с тем, что вам пришлось бы проделывать для управления ведущима указателями без них. Несколько лишних байт для счетчика в ведущим указателе не играют особой роли; к тому же они выделяются в куче, степень детализации которой обычно заметно превышает четыре байта. Возможно, вам стоит вернуться к предыдущим главам и подумать, как использовать показанную схему подсчета ссылок везде, где встечаются ведущие указатели. Это станет ключом к нетривиальному управлению памятью в дальнейших главах. Пространтсва памяти Все эти фокусы образуют фундамент для дальнейшего строительства, но относить их к архитектуре было бы неверно. Для действительно нетривиального управления памятью понадобятся нетривиальные организационные концепции. В простейшем случае вся доступная память рассматривается как один большой блок, из которого выделяются блоки меньшего размера. Для этого можно либо напрямую обратиться к операционной системе с требованием выделить большой блок памяти при запуске, либо косвенно, в конечном счете перепоручая работу операторным функциям ::operator new и ::operator delete. В двух последних главах мы взглянем на проблему с нетривиальных позиций и поделим доступную память на пространства (memory spaces). Пространства памяти - это концепция; ее можно реализовать на основе практически любой описанной выше блочно-ориентированной схемы управления памятью. Например, в одном пространстве памяти может использоваться система напарников, а в другом - списки свободной памяти. Концепция представлена в следующем абстрактном базовом классе: class MemSpace { public: void* Al1ocate(size t bytes) = 0; void Dea11ocate(void* space, size t bytes) = 0; (Если ваш компилятор поддерживает обработку исключений, при объявлении обоих функций следует указать возможность инициирования исключений.) Некоторым пространствам памяти можно не сообщать в функции Dea11ocate() размер возвращаемых блоков; для конкретных схем могут появиться другие функции, но минимальный интерфейс выглядит именно так. Возможно, также будет поддерживаться глобальная структура данных - коллекция всех MemSpace (причины рассматриваются ниже). Коллекция должна эффективно отвечать на вопрос: Какому пространству памяти принадлежит данный адрес? По имеющемуся адресу объекта вы определяете пространство памяти, в котором он живет. В реализации пространств памяти могут быть использованы любые методики, описанные в предыдущей главе: Глобальная перегрузка операторов new и delete (обычно не рекомендуется). Перегрузка операторов new и delete на уровне класса. Использование оператора new с аргументами под руководством клиента. Использование оператора new с аргументами на базе ведущих указателей. Существует немало причин для деления памяти на пространства. Ниже описаны некоторые распространенные стратегии выбора объектов, которые должны находиться в одном пространстве памяти. Деление по классам В предыдущих главах мы говорили об объектах классов, но так и не ответили напрямую на вопрос: как определить класс объекта для имеющегося объекта? Простейшее решение - добавить переменную, которая ссылается на объект класса. К сожалению, оно связано с заметными затратами как по памяти, так и кода конструктора. Однако существуют два других варианта: 1. Хранить указатель на объект класса в ведущем указателе. Получаем те же затраты, но с улучшенной инкапсуляцией. 2. Выделить все экземпляры некоторого класса в одно пространство памяти и хранить указатель на объект класса в начале пространства (см. рисунок). 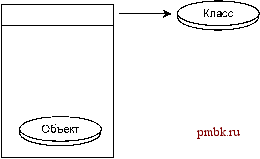 Пространство памяти Второй вариант существенно снижает затраты при условии, что по адресу объекта можно эффективно определить начало адресного пространства памяти, которому он принадлежит (возможно, с помощью упомянутой выше коллекции пространств памяти). На первый взгляд кажется, что устраивать такую суету вокруг простейшей проблемы глупо. Почему бы просто не добавить дополнительную переменную, ссылающуюся на объект класса? Приведу по крайней мере две причины: 1 . Класс, с которым вы работаете, может входить в коммерческую библиотеку, для которой у вас нет исходных текстов, или его модификация нежелательна по другим причинам. 2. Класс может представлять собой тривиальную объектно-ориентированную оболочку для примитивного типа данных (скажем, int). Лишние байты для указателя на объект класса (не говоря уже о v-таблице, которая неизбежно потребуется для виртуальных функций доступа к нему) могут оказаться весьма существенными. Деление по размеру Вполне разумно объединить все объекты одинакового размера (или принадлежащие одному диапазону размеров) в одно пространство памяти для оптимизации создания и уничтожения. Многие стратегии управления памятью работают для одних диапазонов лучше, чем для других. Например, при создании множества больших, сильно различающихся по размерам объектов схема со степенями 2 наверняка оставит много неиспользованных фрагментированных блоков. Однако для объектов относительно малых (или близких по размеру к степеням 2) такая схема работает просто замечательно. В крайних случаях все пространство памяти может заполняться объектами одинакового размера. Такие пространства обладают чрезвычайно эффективным представлением и легко управляются. Деление по способу использования Еще один возможный вариант - делить объекты в соответствии со способом их использования. Например, для многопоточного приложения-сервера объекты можно разделить по клиентам. Редко используемые объекты могут находиться в одном пространстве, а часто используемые - в другом. Объекты, кэшируемые на диске, могут отделяться от объектов, постоянно находящихся в памяти. Деление может осуществляться как на уровне классов, так и на уровне отдельных объектов. Деление по средствам доступа Другая важная причина для разделения по пространствам памяти заключается в том, чтобы хранить по отдельности объекты, доступ к которым осуществляется из стека, из других процессов или чисто
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |