
|
|
Программирование >> Обработка исключительных ситуаций
лава 13 Структуры данных, коллекции л классы-прототипы 3 этой главе приводится обзор основных структур данных, используемых в про-раммировании, и их реализация в библиотеке .NET в виде коллекций. Кроме гого, описываются средства, добавленные в версию С# 2.0, - классы-прототипы [generics), частичные типы (partial types) и обнуляемые типы (nullable types)1. Абстрактные структуры данных Любая программа предназначена для обработки данных, от способа организации которых зависит ее алгоритм. Для разных задач необходимы различные способы хранения и обработки данных, поэтому выбор структур данных должен предшествовать созданию алгоритмов и основываться на требованиях к функциональности и быстродействию программы. Наиболее часто в программах используются следующие структуры данных: массив, список, стек, очередь, бинарное дерево, хеш-таблица, граф и множество. Далее даны краткие характеристики каждой их этих структур. Массив - это конечная совокупность однотипных величин. Массив занимает непрерывную область памяти и предоставляет прямой, или произвольный, доступ к своим элементам по индексу. Память под массив выделяется до начала работы с ним и впоследствии не изменяется. В списке кажд1й элемент связан со следующим и, возможно, с пред1дущим. В первом случае список наз1вается односвязным, во втором - двусвязным. Также применяются термины однонаправленный и двунаправленный. Если последний элемент 1 Остальные средства, появившиеся в версии 2.0, были рассмотрены ранее. Например, итераторы - в главе 9, анонимные методы - в главе 10. связать указателем с первым, получается кольцевой список. Количество элементов в списке может изменяться в процессе работы программы. Каждый элемент списка содержит ключ, идентифицирующий этот элемент. Ключ обычно бывает либо целым числом, либо строкой и является частью данных, хранящихся в каждом элементе списка. В качестве ключа в процессе работы со списком могут выступать разные части данных. Например, если создается список из записей, содержащих фамилию, год рождения, стаж работы и пол, любая часть записи может выступать в качестве ключа: при упорядочивании списка по алфавиту ключом будет фамилия, а при поиске, например, ветеранов труда ключом можно сделать стаж. Ключи разных элементов списка могут совпадать. Над списками можно выполнять следующие операции: добавление элемента в конец списка; чтение элемента с заданным ключом; вставка элемента в заданное место списка; удаление элемента с заданным ключом; упорядочивание списка по ключу. Список не обеспечивает произвольный доступ к элементу, поэтому при выполнении операций чтения, вставки и удаления выполняется последовательный перебор элементов, пока не будет найден элемент с заданным ключом. Для списков большого объема перебор элементов может занимать значительное время, поскольку среднее время поиска элемента пропорционально количеству элементов в списке. Стек - это частный случай однонаправленного списка, добавление элементов в который и выборка из которого выполняются с одного конца, называемого вершиной стека. Другие операции со стеком не определены. При выборке элемент исключается из стека. Говорят, что стек реализует принцип обслуживания LIFO (Last In - First Out, последним пришел - первым ушел). Стек проще всего представить себе как закрытую с одного конца узкую трубу, в которую бросают мячики. Достать первый брошенный мячик можно только после того, как вынуты все остальные. Стеки широко применяются в системном программном обеспечении, компиляторах, в различных рекурсивных алгоритмах. Очередь - это частный случай однонаправленного списка, добавление элементов в который выполняется в один конец, а выборка - из другого конца. Другие операции с очередью не определены. При выборке элемент исключается из очереди. Говорят, что очередь реализует принцип обслуживания FIFO (First In - First Out, первым пришел - первым ушел). Очередь проще всего представить себе, постояв в ней час-другой. В программировании очереди применяются, например, в моделировании, диспетчеризации задач операционной системой, буферизованном вводе-выводе. Бинарное дерево - это динамическая структура данн1х, состоящая из узлов, каждый из которых содержит помимо данных не более двух ссылок на различные бинарные поддеревья. На каждый узел имеется ровно одна ссылка. Начальный узел называется корнем дерева. Абстрактные структуры данных Пример бинарного дерева приведен на рис. 13.1 (корень обычно изображается сверху). Узел, не имеющий поддеревьев, называется листом. Исходящие узлы называются предками, входящие - потомками. Высота дерева определяется количеством уровней, на которых располагаются его узлы. 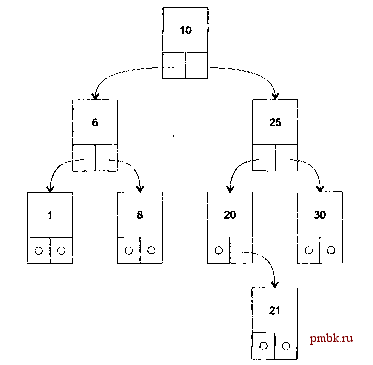 Рис. 13.1. Пример бинарного дерева поиска Если дерево организовано таким образом, что для каждого узла все ключи его левого поддерева меньше ключа этого узла, а все ключи его правого поддерева - больше, оно называется деревом поиска. Одинаковые ключи не допускаются. В дереве поиска можно найти элемент по ключу, двигаясь от корня и переходя на левое или правое поддерево в зависимости от значения ключа в каждом узле. Такой поиск гораздо эффективнее поиска по списку, поскольку время поиска определяется высотой дерева, а она пропорциональна двоичному логарифму количества узлов. Впрочем, скорость поиска в значительной степени зависит от порядка формирования дерева: если на вход подается упорядоченная или почти упорядоченная последовательность ключей дерево вырождается в список. Для ускорения поиска применяется процедура балансировки дерева, формирующая дерево, поддеревья которого различаются не более чем на один элемент. Бинарные деревья применяются для эффективного поиска и сортировки данных. Хеш-таблица, ассоциативный массив, или словарь - это массив, доступ к элементам которого осуществляется не по номеру, а по некоторому ключу. Можно
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.005
При копировании материалов приветствуются ссылки. |