
|
|
Программирование >> Структура ядра и системные вызовы
3. Очень часто процессы создают порожденные процессы, которые выполняют новые программы (например, программу spell). Это позволяет пользователям писать программы, которые могут путем вызова других/ программ расширять свои функциональные возможности, не требуя ввода нового исходного кода. В этой главе рассматриваются структуры данных ядра UNIX, которые поддерживают создание и выполнение процессов, описывается интерфейс системных вызовов, предназначенных для управления процессами, а также приводится ряд примеров, демонстрируюших приемы разработки многозадачных программ в UNIX. 8.1. Поддержка процессов ядром ОС UNIX Структура данных и механизм выполнения процессов зависят от реализации операционной системы. Рассмотрим структуру данных процесса и поддержку его на уровне операционной системы на примере ОС UNIX System V. Таблица процессов Процесс Таблица ядра 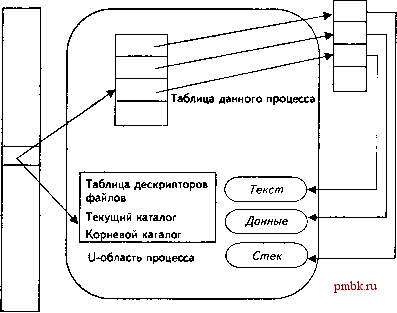 Рис. 8.1. Структура данных UNIX-процесса Из рис. 8.1 видно, что UNIX-процесс состоит как минимум из сегмента текста, сегмента данных и сегмента стека. Сегмент - это область памяти, которой система управляет как единым целым. Сегмент текста содержит текст программы процесса в формате машинных кодов команд. Сегмент 1 данных содержит статические и глобальные переменные с соответствующими данными. Сегмент стека содержит динамический стек. В стеке хранятся аргументы функций, переменные и адреса возврата всех функций, активных в процессе в каждый данный момент времени. В ядре UNIX есть таблица процессов, в которой отслеживаются все активные процессы. Некоторые из них инициируются ядром и называются системными процессами. Большинство процессов связаны с пользователями, зарегистрированными в системе. Каждый элемент таблицы процессов содержит указатели на сегменты текста, данных, стека и U-область процесса. U-область - это расширение записи в таблице процессов, которое содержит дополнительные данные о процессе, в частности таблицу дескрипторов файлов, номера индексных дескрипторов текущего корневого и рабочего каталогов, набор установленных системой лимитов ресурсов процессов и т.д. Все процессы в UNIX-системе, кроме самого первого (процесс с ID равным 0), который создается программой начальной загрузки системы, создаются с помощью системного вызова fork. После завершения системного вызова fork и родительский, и порожденный процессы возобновляют свое выполнение. Таблица процессов Таблица ядра § а а. с
 (нные Стек Данные) Рис. 8.2. Структура данных родительского и порожденного процессов после завершения системного вызова fork *>,) гСудя по рис. 8.2, когда процесс создается функцией fork, он получаетj копии сегментов текста, данных и стека своего родительского процесса. Еще он получает таблицу дескрипторов файлов, которая содержит ссылки на те же Открытые файлы, что имеются и у родительского процесса. Это позволяе- им совместно пользоваться одним указателем на каждый открытый файл, s Кроме того, процессу присваиваются следующие атрибуты, которые либо наследуются от родительского процесса, либо устанавливаются ядром: \ Реальный идентификатор владельца (rUID): идентификатор пользовате-ля, который создал родительский процесс. С помощью этого атрибута ядро следит за тем, кто и какие процессы создает в системе. -т Реальный идентификатор группы (rGID): идентификатор группы, к которой принадлежит пользователь, создавщий родительский процесс. С помощью этого атрибута ядро следит за тем, какая фуппа и какие процессы порождает в системе. Эффективный идентификатор пользователя (eUID): обычно совпадает с rUID, за исключением случая, когда у файла, который был выполнен для создания процесса, установлен флаг set-UID (с помощью команды или API chmod). В этом случае eUID процесса становится равным UID файла. Это позволяет процессу обращаться к файлам и создавать новые файлы, пользуясь такими же привилегиями, как и у владельца выполняемой программы. Эффективный идентификатор группы владельца (еОШ): обычно совпадает с rGID, за исключением случая, когда у файла, который был выполнен для создания процесса, установлен флаг set-GID (с помощью команды или API chmod). В этом случае eGID процесса становится равным GID файла. Это позволяет процессу обращаться к файлам и создавать файлы, пользуясь привилегиями группы, к которой относится программный файл. Saved set-UID и saved set-GID: это назначенные eUID и eGID процесса. Идентификационный номер группы процесса (PGID) и идентификационный номер сеанса (SID): обозначают группу, которой принадлежит процесс, и сеанс, участником которого он является. Дополнительные идентификационные номера группы: набор вспомогательных идентификаторов группы для пользователя, создавшего процесс. Текущий каталог: ссылка (номер индексного дескриптора) на рабочий файл-каталог. Корневой каталог: ссылка (номер индексного дескриптора) на корневой каталог. Обработка сигналов: параметры обработки сигналов. Сигналы рассматриваются в следующей главе. Сигнальная маска: маска, которая показывает, какие сигналы подлежат блокированию. Значение umask: маска, которая используется при создании файлов для установки необходимых прав доступа к ним. Значение nice: значение приоритета процесса. Управляющий терминал: управляющий терминал процесса. Следующие атрибуты у родительского и порожденного процессов разные: Идентификатор процесса (PID): целочисленный идентификатор, уникальный для процесса во всей операционной системе. Идентификатор родительского процесса (PPID): идентификационный номер родительского процесса. Ждущие сигналы: набор сигналов, ожидающих доставки в родительский процесс. Время посылки предупреждающего сигнала: время, через которое процессу будет послан предупреждающий сигнал (устанавливается системным вызовом alarm; в порожденном процессе сбрасывается в нуль). Блокировки файлов: набор блокировок файлов, созданных родительским процессом, порожденным процессом не наследуется. После системного вызова fork родительский процесс может посредством системного вызова wait или waitpid приостановить свое выполнение до заверщения порожденного процесса или продолжать выполнение независимо от порожденного процесса. В последнем случае родительский процесс может с помощью функции signal или sigaction (см. главу 9) выявлять или игнорировать заверщение порожденного процесса. Процесс завершает выполнение при помощи системного вызова exit. Аргументом этого вызова является код статуса заверщения процесса. По соглашению, нулевой код статуса завершения означает, что процесс завершил выполнение успешно, а ненулевой свидетельствует о неудаче. С помощью системного вызова exec процесс может выполнить другую программу. Если вызов вьшолняется успешно, ядро заменяет существующие сегменты текста, данных и стека процесса новым набором, который представляет собой новую подлежащую выполнению программу. Тем не менее процесс остается прежним (поскольку идентификатор процесса и идентификатор родительского процесса одинаковы), и его таблица дескрипторов файлов и открытые каталоги остаются в основном теми же (за исключением дескрипторов, у которых флаг close-on-exec был установлен системным вызовом/с/1 ,- после выполнения exec они будут закрыты). То есть процесс после вызова exec можно сравнить с человеком, меняющим работу. Сменив место работы, он имеет то же имя, те же личные данные, но выполняет другие обязанности. Когда программа, вызванная посредством exec, заканчивает выполнение, она завершает процесс. Код статуса завершения этой программы сообщается родителю данного процесса с помощью функции wait или waitpid. Функции fork и exec, как правило, используются вместе для порождения подпроцесса, предназначенного для выполнения другой подпрограммы. Например, shell в UNIX выполняет каждую команду пользователя путем вызова fork и exec, и затребованная команда выполняется в порожденном процессе. Вот преимущества этого метода: процесс может создавать несколько других процессов для параллельного выполнения нескольких программ; поскольку каждый порожденный процесс выполняется в собственном виртуальном адресном пространстве, статус его выполнения не влияет на родительский процесс. Два или более связанных процесса (родительский с порожденным или порожденный с порожденным, имеющие одного родителя) могут взаимодействовать с другими процессами путем организации неименованных каналов. Несвязанные процессы могут общаться по именованным каналам или с помощью средств межпроцессного взаимодействия, описанных в главе 10. 8.2. API процессов 8.2.1. Функции fork, vfork Системный вызов fork используется для создания порожденного процесса. Прототип функции fork имеет следующий вид: . #ifdef POSIX SOURCE #include <sys/stdtypes.h> #else ;;#include <sys/types.h> #endif jpid t fork ( void ) Функция fork не принимает аргументов и возвращает значение типа pidj (определяемое в <sys/types.h>). Этот вызов может давать один из следующих результатов: Успешное выполнение. Создается порожденный процесс, и функция возвращает идентификатор этого порожденного процесса родительскому. Порожденный процесс получает от fork нулевой код возврата. Неудачное выполнение. Порожденный процесс не создается, а функция присваивает переменной еггпо код ошибки и возвращает значение -1. Ниже перечислены основные причины неудачного выполнения fork и соответствующие значения еггпо: Значение еггпо Причина ENOMEM EAGAIN Для создания нового процесса не хватает свободной памяти Количество текущих процессов в системе превышает установленное системой ограничение, попытайтесь повторить вызов позже Необходимо отметить, что существуют устанавливаемые системой ограничения на максимальное количество процессов, создаваемых одним пользователем (CHILD MAX), и максимальное Количество процессов, одновременно существующих во всей системе (MAXPID). Если любое из этих ограничений при вызове fork нарушается, то функция возвращает код неудачного завершения. Символы MAXPID и CHILD MAX определяются соответственно в заголовках <sys/param.h> и <limits.h>. Кроме того, процесс может получить значение CHILDMAX с помощью функции sysconf: int child max = sysconf ( SC CHILD MAX); При успешном вызове fork создается порожденный процесс. Структура данных родительского и порожденного процессов после вызова fork показана на рисунке 8.2. Как порожденный процесс, так и родительский планируются ядром UNIX для выполнения независимо, а очередность запуска этих процессов зависит от реализации ОС. По завершении вызова fork выполнение обоих процессов возобновляется. Возвращаемое значение вызова fork используется для того, чтобы определить, является ли процесс порожденным или родительским. Таким образом, родительский и порожденный процессы могут выполнять различные задачи одновременно. Использование fork демонстрируется ниже на примере программы test Jork. С. Родительский процесс вызывает fork для создания порожденного процесса. Если fork возвращает -1, значит, системный вызов не выполнился, и родительский процесс вызывает perror для вывода диагностического сообщения в стандартный поток ошибок. Если же fork выполнена успешно, то порожденный процесс после своего выполнения выдает на стандартный вывод сообщение Child process created. Затем он завершается посредством оператора return. Тем временем родительский процесс выводит на экран сообщение Parent process after fork и тоже завершает свою работу. ♦include <iostream.h> ♦include <stdio.h> ♦include <unistd.h> int mainO switch (forkO )[y . { case (pid t)-lt: . perror ( fork ) ; break; case (pid t)0: cout Child process created\n ; return 0; default: cout Parent process after fork\n ; } return 0; /* fork fails */ Выполнение этой программы может дать следующие результаты: % СС -о test fork test fork.C % test fork Child process created Parent process after fork
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |