
|
|
Программирование >> Составные структуры данных
Программа 7.2. Разделение Переменная v сохраняет значение разделяющего элемента а[г], а I и j представляет собой, соответственно, указатели левого и правого просмотра. Цикл разделения увеличивает значение i и уменьшает значение] на 1, причем условие, что ни один элемент слева от i не больше v и ни один элемент справа от j не больше v, не нарушается. Как только значения указателей пересекаются, процедура разбиения завершается, меняя местами а[г] и a[i], при этом v присваивается значение a[i], так что не будет ни одного большего элемента справа от V и ни одного меньшего элемента слева от v. Разделяющий цикл реализуется в виде бесконечного цикла, который прерывается функцией break, когда указатели пересекаются. Проверка j==1 обеспечивает защиту от случая, когда в качестве разделяющего элемента используется наименьший элемент файла. template <class Item> int partition (Item a[] , int 1, int r) { int i = 1-1, j = r; Item v = a[r]; for (;;) while (a[++i] < v) while (v < a[--j]) breake; if (i >= j) breake; exch(a[i], a[j]); if (j == 1) exch(a[i], return i; a[r]); Существуют три основных стратегии, которые можно выбрать применительно к ключам, равным разделяющему элементу: заставить оба указателя останавливаться на таком ключе (как это имеет место в программе 7.2); заставить один указатель остановиться, а другому позволить продолжать просмотр; позволить обоим указателям продолжить просмотр. Вопрос о том, какая из этих стратегий лучше, был тщательно изучен с привлечением математического аппарата, и результаты показали, что наилучшей стратегией является останов обоих указателей главным образом потому, что при этом получается сбалансированное разделение при наличии множества дублированных ключей, в то время как две других стратегии для некоторых видов файлов приводят к ярко выраженному нарушению баланса. В разделе 7.6 рассматривается несколько более сложный и в то же время гораздо более эффективный способ работы с дублированными ключами. 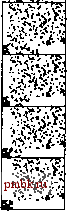 РИСУНОК 7.3. ДИНАМИЧЕСКИЕ ХАРАКТЕРИСТИКИ ПРОЦЕССА РАЗДЕЛЕНИЯ БЫСТРОЙ СОРТИРОВКИ Процесс разбиения делит файл на два подфайла, которые могут подвергаться сортировке независимо друг от друга. Ни один из элементов слева от значения указателя просмотра левого подфайла не может быть больше его, так что выше и левее его на диаграмме точек нет; ни один из элементов справа от значения указателя просмотра правого подфайла не может быть меньше его, так что ниже и правее его на диаграмме точек нет. Из этих двух примеров легко видеть, что разбиение файла с произвольной организацией делит его на два файла меньших размеров с произвольной организацией, при этом один элемент (а именно, разделяющий) занимает свою окончательную позицию на диагонали. В конечном итоге эффективность сортировки зависит от качества разбиения файла, которое, в свою очередь, зависит от выбора значения разделяющего элемента. Рисунок 7.2 демонстрирует, что процедура разделения разбивает крупный файл с произвольной организацией на два файла с произвольной организацией меньших размеров, но при этом точка раздела может оказаться в любом месте файла. Мы предпочитаем выбирать такую точку раздела вблизи от середины файла, однако не располагаем необходимой для этого информацией. Если сортируется файл с произвольной организацией, то выбор элемента а[г] в качестве разделяющого - это то же самое, что и выбор любого другого конкретного элемента; он дает нам в общем случае точку раздела в непосредственной близости от середины. В разделе 7.4 проводится анализ рассматриваемого алгоритма, который позволит сравнить такой случай с идеальным выбором. В разделе 7.5 будет показано, насколько подобного рода анализ может оказаться полезным при выборе разделяющего элемента в целях повышения эффективности рассматриваемого алгоритма. Упражнения > 7.1. Показать в стиле рассмотренного здесь примера, как быстрая сортировка сортирует файл EASYQUESTION. 7.2. Показать, как производится разделение файла 100111000001010 0, используя для этой цели программу 7.2 и несущественные модификации, предлагаемые по тексту. 7.3. Реализовать разделение, не прибегая к помощи операторов break или goto. 7.4. Разработать устойчивую быструю сортировку для связных списков. о 7.5. Каким является максимальное число перемещений наибольшего элемента файла, состоящего из N элементов, во время выполнения быстрой сортировки. 7.2. Характеристики производительности быстрой сортировки Несмотря на все ее ценные качества, базовая программа быстрой сортировки обладает определенным недостатком, который заключается в том, что она исключительно неэффективна на некоторых простых файлах, которые могут встретиться на практике. Например, если она применяется для сортировки файла размером N, который уже отсортирован, то все имеющиеся разделения вырождаются, и программа вызовет сама себя Л раз, перемещая за каждый вызов всего лишь один элемент. Лемма 7.1. Быстрая сортировка в наихудшем случае выполняет примерно N/2 операций сравнения. В силу только что приведенного аргумента-, число операций сравнения, выполненных при сортировке уже отсортированного файла, выражается как 7V+ {N- 1) + (Л- 2) + ... + 2 + 1 = (7V + 1) jV/ 2. Все разделения вырождаются как в случае файла, отсортированного в обратном порядке, так и в случае файлов определенных видов, вероятность столкнуться с которыми на практике существенно ниже (см. упражнение 7.6). Подобное поведение означает не только то, что время выполнения быстрой сортировки приближенно определяется зависимостью N/2, но и то, что пространство памяти, необходимое для выполнения этой рекурсии, примерно пропорционально N (см. раздел 7.3), что в случае крупных файлов недопустимо. К счастью, имеются сравнительно простые способы существенного снижения вероятности того, что наихудший случай возникнет в типовых применениях рассматриваемой программы. Наиболее благоприятный для быстрой сортировки случай имеет место, когда на каждой стадии разбиения файл делится на две равные части. Это обстоятельство приводит к тому, что количество операций сравнения, выполняемых в процессе быстрой сортировки, удовлетворяет реккурентному соотношению типа разделяй и властвуй . С== + Член 2 С/у/2 соответствует затратам на сортировку двух подфайлов; N суть затраты на проверку каждого элемента, для чего используется тот или иной разделяющий указатель. Из главы 5 уже известно, что это рекуррентное соотношение имеет решение CNlgN Несмотря на то что не всегда все так удачно складывается, тем не менее, верно, что в среднем разделение попадает на середину файла. Если еще учесть точную вероятность каждой позиции разделения, то указанное выше рекуррентное соотношение становится более сложным и более трудным для решения, однако окончательный результат примерно такой же. Лемма 7.2. Быстрая сортировка в среднем выполняет 2 TV In TV операций сравнения. Точное рекуррентное соотношение для определения числа сравнений, выполняемых во время быстрой сортировки N случайно распределенных различных элементов, имеет вид C;v=iV-Hl-H 5(Q ,+CAr-0 ДЛЯ N>2, \<k<N при Ci = Со = 0. Член TV + 1 учитывает затраты на выполнение операций сравнения разделяющего элемента с каждым из остальных элементов (два дополнительных в точке пересечения указателей); наличие остальных компонентов обусловлено тем фактом, что каждый элемент к может стать разделяющим элементом с вероятностью \/к, после чего остаются файлы с произвольной организацией, имеющие размеры к - \ и N - к. Это рекуррентное соотношение, несмотря на внешнюю сложность, фактически довольно просто решается, буквально за три действия. Во-первых, Со + С\ +...+ Сдг-! есть ни что иное как Cf-\ + Сл-2 +...+ Со; следовательно, имеем \<k<N Во-вторых, можно избавиться от суммы, если умножить обе части равенства на Л и вычесть такую же формулу для N - 1 NCj-(N- 1)С , = NiN+ 1)-(УУ- l)yv+ 2Cv-.l
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |