
|
|
Программирование >> Составные структуры данных
#include <iostream.h> #include <stdlib.h> #include list.h int main(int argc, char *argv[]) { int i, N = atoi (argv[l]) , M = atoi (argv[2]) ; Node t, X ; construct(N); for (i = 2, X = newNode(l),- i <= N; i++) { t = newNode(i); insert(x, t) ; x = t; } while (X != next(x)) { for (i = 1; i < M; i++) x = next(x); deleteNode (remove (x)) ; cout item(x) endl; return 0; Некоторые программисты предпочитают инкапсулировать все операции в низкоуровневых структурах данных, таких как связные списки, путем описания функция для каждой низкоуровневой операции в интерфейсах, подобных показанному в программе 3.12. Действительно, как будет продемонстрировано в главе 4, классы С++ упрощают это рещение. Однако такой дополнительный уровень абстракции иногда скрывает факт использования небольшого количества операций низкого уровня. В данной книге при реализации высокоуровневых интерфейсов низкоуровневые операции обычно описываются непосредственно в связных структурах, дабы ясно выразить существенные подробности алгоритмов и структур данных. В главе 4 будет рассматриваться множество примеров. За счет добавления ссылок можно реализовать возможность обратного перемещения по связному списку. Например, применение двухсвязного списка (double linked list) позволяет поддерживать операцию найти элемент, предшествующий данному . В таком списке каждый узел содержит две ссылки: одна (prev) указывает на предыдущий элемент, а другая (next) - на следующий. Наличие фиктивных узлов либо цикличность двухсвязного списка позволяет обеспечить эквивалентность выражений x->next->prev и x->prev->next для каждого узла. На рис. 3.9 и 3.10 показаны основные действия со ссылками, необходимые для реализации операций remove (удалить), insert after (вставить после) и insert before (вставить перед) в двухсвязных списках. 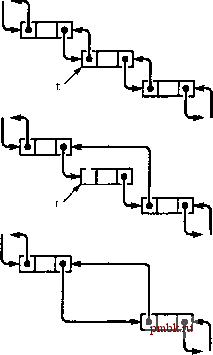 РИСУНОК 3.9 УДАЛЕНИЕ В ДВУХСВЯЗНОМ СПИСКЕ В двухсвязном списке указатель узла предоставляет достаточно информации для удаления узла, что видно из диаграммы. Для данного t указателю t- >next- >prev присваивается значение t- >prev (средняя диаграмма), а указателю t->prev->next - значение t->next (нижняя диаграмма). Обратите внимание, что для операции удаления не требуется дополнительной информации об узле, предшествующем данному (либо следующим за ним) в списке, как это имеет место для односвяз-ных списков - эта информация содержится в самом узле. Действительно, главная особенность двухсвязных списков состоит в возможности удаления узла, когда ссылка на него является единственной информацией об узле. Типичны случаи, когда ссылка передается при вызове функции в качестве аргумента, а также если узел имеет другие ссылки и сам является частью другой структуры данных. Предоставление этой дополнительной возможности влечет удвоение пространства, отводимого под ссылки в каждом узле, а также количества операций со ссылками на каждую базовую операцию. Поэтому двухсвязные списки обычно не используются, если этого не требуют условия. Рассмотрение подробных реализаций отложим до обзора нескольких особых случаев, где в этом возникнет необходимость - например, в разделе 9.5 Связные списки используются в материале книги, во-первых, для основных ADT-реализаций (см. главу 4), во-вторых, в качестве компонентов более сложных структур данных. Для многих про-фа*лмистов связные списки являются первым знакомством с абстрактными структурами данных, которыми разработчик может непосредственно управлять. Они образуют важное средство разработки высокоуровневых абстрактных структур данных, необходимых для решения множества задач, в чем будет возможность убедиться. Упражнения > 3.33 Создать функцию, которая перемещает наибольший элемент данного списка так, чтобы он стал последним узлом. 3.34 Создать функцию, которая перемещает наименьший элемент данного списка так, что- ODtb ПГгЬ РИСУНОК 3.10 ВСТАВКА В ДВУХСВЯЗНОМ СПИСКЕ Для вставки узла в двухсвязный список необходимо установить четыре указателя. Можно вставить новый узел после данного узла (как показано на диаграмме) либо перед ним. Для вставки узла t после узла х указателю t- >next присваивается значение х- >next, а указателю х->next->prev - значение t (средняя диаграмма). Затем указателю x->next присваивается значение t, а указателю t- >prev - значение х (нижняя диаграмма). бы он стал первым узлом. 3.35 Создать функцию, которая перераспределяет связный список так, чтобы узлы в четных позициях следовали после узлов в нечетных позициях, сохраняя порядок сортировки четных и нечетных узлов. 3.36 Реализовать фрагмент кода для связного списка, меняющий местами узлы, которые следуют после узлов, указываемых ссылками t и и. о 3.37 Создать функцию, которая принимает ссылку на список в качестве аргумента и возвращает ссылку на копию списка (новый список, содержащий те же элементы в том же порядке). 3.38 Создать функцию, принимающую два аргумента - ссылку на список и функцию, принимающую список в качестве аргумента - и удаляет все элементы данного списка, для которых функция возвращает ненулевое значение. 3.39 Выполнить упражнение 3.38, но создать копии узлов, которые проходят проверку и возвращают ссылку на список, содержащий эти узлы, в порядке их следования в исходном списке. 3.40 Реализовать версию программы 3.10, в которой используется фиктивный узел. 3.41 Реализовать версию программы 3.11, в которой не используются фиктивные узлы. 3.42 Реализовать версию профаммы 3.9, в которой используется фиктивный узел. 3.43 Реализовать функцию, которая меняет местами два данных узла в двухсвязном списке. о 3.44 Создать запись табл. 3.1 для списка, который никогда не бывает пустым. На этот список ссылается указатель первого узла, а последний узел содержит указатель на самого себя. 3.45 Создать запись табл. 3.1 для циклического списка, имеющего фиктивный узел, который служит ведущим и завершающим узлом. 3.5 Распределение памяти под списки Преимущество связных списков перед массивами состоит в том, что связные списки эффективно изменяют размеры на протяжении времени жизни. В частности, необязательно заранее знать максимальный размер списка. Одно из важных практических следствий этого свойства состоит в возможности иметь несколько структур данных, обладающих общим пространством, не уделяя особого внимания их относительному размеру в любой момент времени. Интерес представляет реализация оператора new. Например, при удалении узла из списка задача сводится к перераспределению ссылок таким образом, чтобы узел более не был привязан к списку. А как поступает система с пространством, которое этот узел занимал? Как система утилизирует пространство, чтобы всегда иметь возможность выделять его под новый узел в операторе new? За этими вопросами стоят механизмы, которые служат еще одним примером эффективности элементарной обработки списков. Оператор delete дополняет оператор new. Когда блок выделенной памяти более не используется, вызывается оператор delete для информирования системы о том, что блок доступен для дальнейшего использования. Динамическое распределение памяти (dynamic memory allocation) - это процесс управления памятью и ответных действий на вызов операторов new и delete из клиентских программ. При вызове оператора new непосредственно из приложений, таких как программы 3.9 или 3.11, запрашиваются
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |