
|
|
Программирование >> Составные структуры данных
рактеристики производительности с характеристиками trie-дерева из упражнения 15.69. о 15.72 Создайте генератор ключей, который генерирует 30-байтовые случайные строки, состоящие из трех полей: 4-байтового поля, содержащего одну из 10 заданных строк, 10-байтового поля, содержащего одну из 50 заданных строк, 1-байтового поля, содержащего одно из двух заданных значений, и 15-байтового поля, содержащего случайные, выровненные по левому краю буквенные строки, длина которых с равной вероятностью может составлять от четырех до 15 символов (см. упражнение 10.23). Воспользуйтесь этим генератором ключей для построения 256-путевого trie-дерева, содержащего случайных ключей при Л= 10, iC, 10* и 10, с применением операции search, а затем - операции insert в случае промаха при поиске. Программа должна выводить общее количество узлов в каждом trie-дереве и общее время, затраченное на построение каждого /пе-дерева. Сравните полученные характеристики производительности с характеристиками для случайных строковых ключей (см. упражнение 15.69). 15.73 Выполните упражнение 15.72 для случая TST-деревьев. Сравните полученные характеристики производительности с характеристиками для trie-деревьев. 15.74 Разработайте реализацию операций search и insert для ключей в виде строк байтов при использовании многопутевых деревьев поразрядного поиска. 1> 15.75 Нарисуйте 27-путевое DST-дерево (см. упражнение 15.74), образованное в результате вставки элементов с ключами now is the time for all good people to come the aid of their party в первоначально пустое DST-дерево. 15.76 Разработайте реализацию поиска и вставки в многопутевое trie-дерево, в котором связные списки применяются для представления узлов trie-дерева (в отличие от представления в виде BST-дерева, которое используется для TST-деревьев). Определите экспериментальным путем, что использовать эффективнее: упорядоченные или неупорядоченные списки, и сравните эту реализацию с реализацией, основанной на использовании TST-деревьев. 15.5 Алгоритмы индексирования текаовых арок В разделе 12.7 был рассмотрен процесс построения строкового индекса, и BST-дерево со строковыми указателями использовалось для обеспечения возможности определения того, присутствует ли строка с заданным ключом в очень большом тексте. В этом разделе будут рассмотрены более сложные алгоритмы использования многопутевых trie-деревьев, но отправная точка при этом остается той же. Каждая позиция в тексте считается началом строкового ключа, который простирается до конца текста; за счет использования строковых указателей из этих ключей строится таблица символов. Все ключи различны (например, имеют различную длину) и большинство из них очень велики. Цель поиска - определить, является ли заданный искомый ключ префиксом одного из ключей в индексном указателе, что эквивалентно выяснению того, присутствует ли искомый ключ где-либо в текстовой строке. Дерево поиска, которое построено из ключей, определенных строковыми указателями внутри текстовой строки, называется деревом суффиксов. Можно воспользоваться любым алгоритмом, допускающим существование ключей переменной длины. В этом случае особенно подходят методы, основанные на применении trie-деревь- ев, поскольку (за исключением методов с использованием trie-деревьев, выполняющих однопутевое ветвление в окончаниях ключей) их время выполнения зависит не от длины ключей, а только от количества цифр, необходимых для различения. Это прямо противоположно, например, алгоритмам хеширования, которые нельзя непосредственно применить для решения этой задачи, поскольку их время выполнения пропорционально длине ключей. На рис. 15.20 приведены примеры строковых индексов, построенных с использованием BST-деревьев, patricia-деревьев и TST-деревьев (с листьями). В этих индексах используются только ключи, которые начинаются с граничных символов слов; индексирование, начинающееся с границ символов, обеспечило бы более сложное индексирование, но при этом использовался бы гораздо больший объем памяти. Строго говоря, даже текст, состоящий из случайной строки, не позволяет случайному набору ключей превратится в соответствующий индекс (поскольку ключи не являются независимыми). Однако, в используемых на практике приложениях индексирования редко приходится иметь дело со случайными текстами, и это теоретическое несоответствие не помешает нам воспользоваться преимуществом эффективных реализаций индексирования, которые поддерживают поразрядные методы. Мы воздержимся от подробного рассмотрения характеристик производительности при использовании каждого из алгоритмов для построения строкового индекса, поскольку многие ограничения, проанализированные для общих таблиц символов со строковыми ключами, действуют также и при решении задачи индексирования строк. 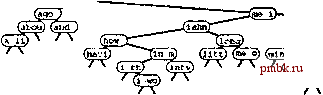 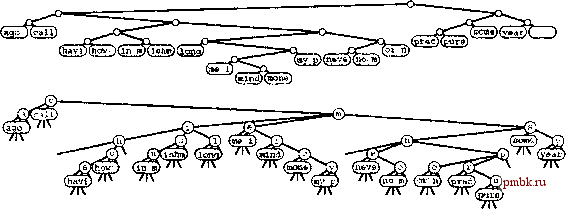 РИСУНОК 15.20 ПРИМЕРЫ ИНДЕКСИРОВАНИЯ ТЕКСТОВЫХ СТРОК На этих схемах показаны индексы текстовых строк, построенные из текста call те ishmael some years ago nevermind how long precisely... с использованием BST-дерева (вверху), patricia-дерева (в центре) и TST-дерева (внизу). Узлы, содержащие строковые указатели, отображены первыми четырьмя символами, расположенными в указываемой указателем точке. В случае типового текста реализации с использованием стандартных BST-деревьев, вероятно, должны быть рассмотрены в первую очередь, поскольку их легко реализовать (см. программу 12.10). Скорее всего, для типовых приложений это решение должно обеспечивать хорошую производительность. Один из побочных эффектов взаимной зависимости ключей - особенно, при построении строкового индекса для каждой позиции символа - то, что худший случай BST-деревьев не порождает особые проблемы в очень больших текстах, поскольку несбалансированные BST-деревья возникают только в исключительно причудливых конструкциях. patricia-деревья изначально разрабатывались для приложений строкового индексирования. Для использования профамм 15.5 и 15.4 пофебуется лишь обеспечить реализацию функции bit, чтобы при заданном строковом указателе и целочисленном значении / она возвращала /-тый разряд строки (см. упражнение 15.82). На практике зависимость высоты patricia-дерева, реализующего индекс текстовой строки, будет логарифмической. Более того, patricia-дерево обеспечит быстрые реализации поиска для обнаружения промахов, поскольку нет необходимости исследовать все байты ключа. TST-деревья предоставляют несколько преимуществ в плане произтодительности, характерных для patricia-деревьев, их просто реализовать и они используют преимущества встроенных операций доступа к байтам, которые в современных компьютерах обычно реализованы. Кроме того, они поддаются простым реализациям, подобным программе 15.9, которые могут решать и более сложные задачи, нежели установка полного соответствия с искомым ключом. Чтобы использовать TST-деревья для построения строкового индекса, необходимо удалить код, обрабатывающий конечные части ключей в структуре данных, поскольку ни одна строка не является префиксом другой и, следовательно, никогда не придется сравнивать строки вплоть до их конечных символов. Эта модификация включает в себя изменение определения operator== в интерфейсе типа элемента, чтобы две строки считались равными, если одна из них - префикс другой, как это было сделано в разделе 12.7, поскольку мы будем сравнивать ключ поиска (короткий) с текстовой строкой (длинной), начиная с некоторой позиции текстовой строки. Третье удобное изменение - хранение в каждом узле строковых указателей, а не символов, чтобы каждый узел в дереве ссылался на позицию в текстовой строке (позицию, следующую за первым вхождением строки, определенной символами в равных ветвях от корня до этого узла). Реализация перечисленных изменений - интересное и поучительное упражнение, ведущее к созданию гибкой и эффективной реализации индексирования текстовых строк (см. упражнение 15.81). Несмотря на все описанные преимущества, имеется одно важное обстоятельство, которым мы пренебрегли при рассмотрении использования BST-деревьев, patricia-деревьев или TST-деревьев для типичных приложений индексирования текста: сам по себе текст фиксирован, поэтому нет необходимости поддерживать динамические операции insert, как мы привыкли это делать. То есть, как правило, индекс строится один раз, а затем без каких-либо изменений используется для выполнения офомного объема поисков. Следовательно, динамические структуры данных типа BST-деревьев, patricia-деревьев или TST-деревьев могут оказаться вообще не нужными. Базовый алгоритм, подходящий в данной ситуации - бинарный поиск с использованием стро-
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |