
|
|
Программирование >> Рекурсивные объекты и фрактальные узоры
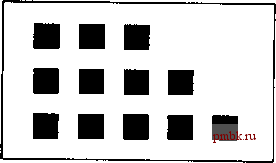 Рнс. 6.6. Начальное расположение фишек для игры в ним ГЛАВА 7. моделирование вероятностных процессов Коттеджный поселок на Рублевке оккупировала стая ежей В тайге найдена канарейка Дзержин.ского Как заметил писатель Том Клэпси, в жизни нет гарантий, существуют одни вероятности. Действительно, на практике очень часто встречаются задачи, в которых так или иначе фигурируют случайные величины. В этой главе мы обсудим несколько различных типов задач, по-разному связанных с вероятностями. В разделе Рандомизирова1П1ые алгоритмы обсуждаются процедуры, формирующие частично случайтаю выходные данные. Например, если вы желаете создать газетный заголовок или рекламный слоган по шаблону, программа должна выдавать разные результаты, а не один и тот же набор слов при каждом запуске. Под заголовком Компьютерные эксперименты объединены задачи, посвященные моделированию какого-либо реального процесса, имеющего вероятностную природу Например, мы можем прикинуть, сколько прибыли принесёт интернет-провайдеру установка прокси-сервера (см. п. 7.2.4), но не в состоянии произвести точный подсчёт. В секции биологические модели описаны две псевдобиологические имитации, в которых без случайного элемента тоже обойтись нельзя. 7.1. РАНДОМИЗИРОВАННЫЕ АЛГОРИТМЫ 7.1.1. Генерация заголовков Формирование предлохсений по шаблону Недавно в интернете я наткнулся на заметку о том, что некто bugzzz и mixedb за несколько часов сочинили для конкурса, проводимого Экспресс-газетой , десятки интригующих заголовков статей. Вот некоторые из них: Илью Лагутенко воспитал бородатый краб Бомжи с Манежной площади построили ракету из банок Старого Мельника Московское метро вырыли крысы Магазинная колбаса содержит плутоний Вероятно, такие заголовки с не меньшим успехом сможет выдумывать и компьютер. Задача заключается в реализации системы генерации заголовков. Каждый заголовок создаётся по случайно выбранному шаблону. Любой шаблон, в свою очередь, представляет собой строку, состоящую из названий частей речи и звёздочек, например: ПРИЛ* СУПиИП ГЛАГ ПРИЛ* СУ1Ц ВП Здесь ПРИЛ* означает произвольное количество прилагательных (включая нуль), СУЩ ИП - существительное в именительном падеже, ГЛЛГ - глагол, а СУ1и ВП - существительное в винительном падеже. Такому шаблону, в частности, соответствует заголовок Магазинная колбаса содержит плутоний . Части речи берутся из словаря, поставляемого пользователем. Естественно, поскольку разговор идёт о русскоязычных текстах, придётся хранить в словаре различные формы одного и того же слова (чтобы не было проблем с падежами, родами и числами). 7.1.2. Генератор текста Применение цепей Маркова Тему автоматической генерации текста компьютером продолжает следующая классическая задача. Используя входной текстовый файл в качестве образца для подражания, сгенерировать несколько осмысленных предложений. Традиционно решение связывается с использованием цепей Маркова. Вкратце идея выглядит следующим образом. Предварительная фаза работы заключается в том, чтобы, проанализировав текстовый файл, построить таблицу, сопоставляющую любым К по/ ряд идущим словам список слов, после них встречающихся, и вероятность каждого конкретного варианта. Так, таблица солцне светит иван родил ярко О.6 жарко О.3 тускло О.1 девчонку 1.О для К = 2 означает, что после фразы солнце светит может встретиться одно из трёх слов: ярко , жарко или тускло , причём, скорее всего (с вероятностью 0.6) мы встретим слово ярко . За фразой же иван родил всегда следует слово девчонку . Знаки препинания в данном случае тоже считаются словами, поэтому они будут включены в таблицу. Параметр К влияет на стилистику и разнообразие генерируемых программой фраз. Разумно поэкспериментировать с небольшими значениями - К=1,К = 2,К = 3. Итак, требуется создать текст, состоящий из N (N вводится с клавиатуры) слов. Изначально берётся любая последовательность К слов из таблицы и случайно генерируется следующее слово (при этом вероятность генерации того или иного слова должна соответствовать вероятностям из таблицы). Теперь текст содержит К + 1 слово. Далее берутся К последних слов текста (то есть только что сгенерироващюе слово и К - 1 предшествующих ему) и операция повторяется для них. Процесс продолжается, пока итоговый текст не будет содержать N слов. Программа должна считывать с клавиатуры значения К и N, а затем печатать N слов связного текста на основе входного текстового файла. Мне встречались программы, таблицы вероятностей которых были построены на основе каких-то научных текстов. Сгенерированные этими программами предложения вполне годились в качестве наукообразной воды для всякого рода рефератов, дипломных работ и тому подобных отчётов. Решение Решение этой задачи состоит из двух этапов. На первом этапе создаётся таблица вероятностей для произвольного К, на втором генерируется выходной текст. таблица вероятностей: сопоставляет списку из К слов К+1-е слово и вероятность его появления map<list<string>, map<string, double> > Prob; int К, N; входные параметры задачи const int PrecCoeff =50; точность генератора случайных чисел функция заполняет таблицу вероятностей по данным файла filename void Analyze(const strings filename) таблица частот map<list<string>, map<string, int> > Freq; частоты К-элементных списков слов map<list<string>, int> Count; ifstream file(filename.c str()); очередной список из К слов list<string> Key; string temp; считать первые К слов for(int i = 0; i < К; i++) { file temp; Key.push back(temp); } пока не достигнут конец файла while(file temp) обновить таблицы частот Count[Кеу]++; FreqlKey]{temp]++; очередное слово идёт в конец списка, а первый элемент списка удаляется Key.push back(temp); Key.pop front(); таблица вероятностей создаётся на основе данных таблиц частот. если сочетание Key из К слов встречается в тексте Count[Key] раз, а сочетание (Key, word) - Freq[Key][word] раз, то Prob[Key][word] = Freq[Key][word] / Count[Keyl for {map<list<string>, inap<string, int> >::iterator p - Freq.beginO; p ! Freq.endO ; p+ + ) for(map<string, int>::iterator q - p->second.beginО; q p->second.end(); q++) Prob[p->first][q->first] - q->second / double(Count[p->first]); Для генерации текста необходимо уметь выбирать очередное случайное слово с учётом вероятностей, записанных в таблицу. Этим занимается функция GetRandomWord(): выбрать случайное слово на основе таблицы (слово1, вероятность1), (слово2, вероятность2), (словоЗ, вероятностьЗ),..., (словом, вероятностьМ) string GetRandomWord(const map<string, double>& wordtable) vector<string> words; for(map<string, double>::const iterator p = wordtable.begin(); p != wordtable.endO; p++) fill n(back inserter(words), PrecCoeff*p->second, p->first); if(words.empty О) { cout Невозможно сгенерировать очередное слово! ; exit(O); }
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |