
|
|
Программирование >> Рекурсивные объекты и фрактальные узоры
В юшге невозможно привести приемлемые входные данные, занимающие сотни килобайт. Я перечислю только документы, входившие в мою тестовую коллекцию - небольшую подборку фантастической литературы, ска-ча1П1ую из интернет-библиотеки www .lib.ru: Кир Булычёв: Котёл , Выбор , Смерть этажом ниже, часть I , Смерть этажом ниже, часть II , Доказательство , Лиловый шар ; Артур Конан Дойл: Затерянный мир, часть I , Затерянный мир, часть II , Дезинтеграционная машина , Страна туманов, часть I , Страна туманов, часть II , Когда Земля вскрикнула ; Станислав Лем: Футурологический конгресс , Кибериада , Патруль , Следствие , Терминус , Испытание ; Клиффорд Саймак: Строительная площадка , Империя, часть I , Империя, часть II , На Юпитере , Братство талисмана, часть I , Братство талисмана, часть П . В качестве классифицируемых рассматривались четыре документа: Заповедник сказок Булычёва, Патруль Лема, Магистраль вечности и Зачарованное паломничество Саймака. В результате Магистраль вечности была приписана программой Конан Дойлу, остальные же документы оказались классифицированы правильно. 6.1.4. Распознавание языка документа Классификация документов на разных языках Эта задача завершает тему разработки метрики для множества текстовых документов. На сей раз смысл задачи заключается в разработке системы, автоматически определяющей язык входного текстового файла. Особенной широты охвата не требуется: достаточно научить компьютер восьми-десяти наиболее распространённым европейским языкам. Больше к формулировке задания мне добавить нечего. (Зднако некоторые замечания технического характера, думаю, будут уместными. В предыдущих задачах приходилось сравнивать между собой текстовые документы. Здесь, конечно, вам тоже потребуется провести анализ коллекции файлов для каждого конкретного языка, но во время работы программы эти коллекции уже не нужны. Метрика, скорее всего, будет учитывать какие-то общие черты, присущие всему языку (средняя длина слова, популярные буквосочетания, частота использования тех или иных букв), а не какому-то конкретному документу. Таким образом, в готовой программе будет присутствовать лишь таблица со значениями, выявленными на этапе анализа коллекций. Теперь что касается работы с документами на разных языках. Сейчас уже почти везде доступна поддержка стандарта Unicode, то есть символов, закодированных не одним байтом, как это было раньше, а двумя. Считается, что уж в два байта можно запихнуть едва ли не все символы, когда-либо изобретённые человечеством, и, тем самым закрыть тему сложностей, связанных с многоязыковой поддержкой. Так это или нет, покажет время. Тем не менее, от поддержки старого ASCII-формата в обозримом будущем вряд ли откажутся. Я предлагаю для простоты ограничиться как раз ASCII-файлами. Напомню, как устроена од1юбайтная таблица символов. Первые 128 элементов стандартны: им соответствуют цифры, скобки, знаки препинания, некоторые специальные символы (вроде #, & или =), а также заглавные и строчные латинские буквы. Вы можете быть уверены, что заглавная латинская буква Л в любом тексте, будь то шведский, английский или русский, закодирована числом 65. Вторая половина таблицы отдана на откуп символам национальных алфавитов. В европейских языках к ним относятся забавные буквы наподобие 6, а или 2. В русском же национальными считаются вообще вес символы кириллицы. 6 Зак. 772 Функция main () формирует кластеры и классифицирует некоторый новый документ методом KNN: int main(int argc, char* argv[]) { vector<list<Document>> Clusters(4); Clusters[0] .push jDack(Document ( LibraryWBulychevWBQILER.TXT )) ; Clusters[0].push back(Document(-Library\\Bulychev\\CHOICE.txt )); ... Clusters[3].push back(Document(-Library\\Simak\\TALISMANl.txt-)); Clusters [3] . pushjDack (Document ( Library WSimak \\TALISMAN2.txt-) ) ; Document dl(Library\\Bulychev-RESERVE.txt ); cout Classify(dl. Clusters, 3) endl; return 0; Разработка простой экспертной системы Нередко программной системе приходится принимать решения в сложных, неоднозначных ситуациях. В таких случаях непросто придумать хорошую стратегию, разумно работающую в любых обстоятельствах. Например, тяжело явным образом запрограммировать правильную реакцию пилота самолёта на те или иные показания приборов. То же самое можно сказать о реакции управляемого компьютером каратиста на действия соперника в игре-файтинге. Если придумать свою стратегию затруднительно, можно пойти другим путём - проанализировать действия человека в различных возникающих ситуациях и вывести из них закономерности. Один из возможных способов поиска закономерностей состоит в построении дерева прршятия решений. Рассмотрим, например, такую задачу. Требуется выбрать наилучший способ проведения досуга в зависимости от времени года, погоды и настроения. Результаты опроса людей записаны в текстовом файле: зима солнечно отличное зима солнечно хорошее зима пасмурно отличное весна пасмурно плохое лето солнечно хорошее лето солнечно плохое осень солнечно отличное на каток в гости в гости в бар на пляж в бар на футбол На основе статистического анализа файла компьютер может построить дерево, изображённое на рис. 6.4. отличное  вбар погода пасылрно Время года на каток на футбол 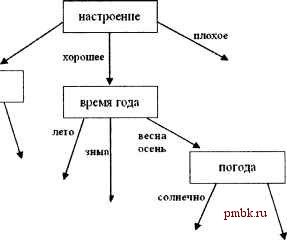 вгостп весна на П.11ЯЖ лето .осень в гостп в гости в бар Рис. 6.4. Дерево принятия решений для задачи проведения досуга Заметьте, дерево позволяет определить правильное решение для любой введённой тройки атрибутов (время года, погода, настроение), независимо от того, присутствует ли она в исходной базе данных или нет. Компьютер начинает с корня дерева. Значение атрибута, записанного в очередном узле, направляет поиск по соответствующей ветви. Каждый терминальный узел дерева содержит в себе решение, наилучшим образом подходящее для введённой ситуации. Таким образом, в документе никак не закодирована информация о языке. Правильный вывод символов - проблема программы, текст отображающей, а не самого текста. Например, что такое символ с кодом 228? Если документ русскоязычный, это буква д (стандарт Windows-1251), а если, скажем, финноязычный, то буква а (стандарт Latin-1, ISO-8859-1). Различные программы решают сложившееся затруднение по-разному. Текстовый редактор, скорее всего, выберет язык, установленный в системе по умолчанию. А, скажем, хороший браузер попытается определить язык автоматически (если вы ещё не забыли, распознавание языка и составляет суть задачи), но при этом оставит возможность пользователю выбрать правильную кодировку из списка. Решение Эта задача несравнимо проще предыдущей. В исходном коде мало что меняется, поэтому приводить его здесь не буду. Функция расстояния представляет собой нормированное скалярное произведение векторов, состоящих из вероятностей всех возможных сочетаний из двух букв алфавита. Например, если каждое сотое буквосочетание в языке - аЬ , то соответствующему элементу вектора сопоставляется число 1/100. Поскольку АЗСП-таблица состоит из 256 символов, количество элементов в каждом векторе будет равно 256*256 = 65536. Можно и сократить объем занимаемой памяти, потому что большинство двухбайтных сочетаний никогда не встречаются в текстовых файлах независимо от их языка. По крайней мере, для небольпюго количества языков эта* методика работает весьма неплохо. 6.1.5. Дерево принятия решений Первым делом необходимо избавиться от противоречивой информации с помощью голосования : из файла выбираются строки с одинаковыми наборами атрибутов, но разными значениями V. Производится голосование , и все проигравшие строки удаляются. Далее можно воспользоваться очевидным наивным алгоритмом построения дерева. В корень записывается атрибут А,. Непосредственными потомками корня будут узлов, каждому из которых сопоставляется множество записей с одинаковым значением атрибута Aj. Возвращаясь к примеру, предположим, что атрибутом Aj считается настроение. Тогда у корневого элемента будет три потомка (для отличного, хорошего и плохого настроения). Соответствегпю, все записи окажутся разбитыми на три группы в соответствии со значением атрибута Aj. Аналогично, для каждого из узлов-потомков корня создаётся дочерних узлов с атрибутом А2. Как только все записи, сопоставленные некоторому узлу дерева, будут содержать одно и то же значение V, обработка ветви считается завершённой. В худшем случае все N атрибутов окажутся задействованными, то есть будет создана ветвь глубиной в N узлов. Например, в нашем случае отличное настроение и солнечная погода ещё не позволяют определить наилучший способ времяпрепровождения: требуется информация и из третьего атрибута время года . Если же настроение плохое, все записи базы данных предлагают V = вбар , и продолжать анализ ветви нет смысла. Недостаток наивного алгоритма в том, что полученное дерево может оказаться куда ветвистее , чем того требует задача. Например, выбрав в качестве корня атрибут настроение , мы сразу же нашли решение для всех ситуаций с плохим настроением, избавившись от необходимости классификации по двум оставшимся атрибутам. Вполне вероятно, что выбор атрибута погода в качестве корневого мог бы привести к созданию итогового дерева большего объёма. Таким образом, при необходимости разделить множество ситуаций на подмножества, мы всякий раз сталкиваемся с задачей выбора наилучшего атрибута. Хотя оптимального решения для этой задачи не существует, было предложено несколько эвристических критериев, неплохо работающих на практике. Здесь я опишу идею Р. Куинлена, использующуюся, например, в популярном алгоритме построения деревьев принятия решений С4.5. J. Ross Quinlan. C4.5: Programs for Machine Learning. Morgan Kaufnnann Publishers, 1993 Деревья принятия решений могут использоваться и для выявления закономерностей в существующей базе данных. Например, проанализировав информацию о возрасте, росте, весе и национальности призёров международных соревнований по бегу, можно выяснить, каким набором атрибутов обычно характеризуются победители, и даже какова степень важности того или иного атрибута. Итоговая задача заключается в разработке алгоритма, находящего дерево принятия решений для любого входного файла с описаниями ситуаций. В каждой строке файла записано N слов, первые N - 1 из которых задают сложившееся положение, а последнее - реакцию человека. Начальные N - 1 строк файла содержат имена используемых атрибутов. На выходе программа выводит дерево в любом читабельном виде, а также позволяет пользователю определить принятое решение для любого введённого с клавиатуры набора атрибутов. Подумайте над алгоритмом построения дерева самостоятельно. Разумный алгоритм может попытаться уменьшить общее количество узлов дерева, но это скорее пожелание, чем обязательное требование. Вполне возможно, что некоторые данные из базы будут друг другу противоречить (человеку никто не мешает пойти в одних и тех же обстоятельствах один раз на футбол, а другой раз - в гости; аналогично, даже не попадающий в число претендентов на победу с точки зрения статистики бегун может всё-таки выиграть). В этом случае итоговое решение выбирается голосованием: в дерево будет записано более часто используемое в исходном файле решение. Неплохо бы также вывести, скольким ситуациям (в процентах) из исходной базы данных с помощью построенного дерева сопоставляются правильные с точки зрения человека решения. Подсказка С точки зрения программирования эта задача мне представляется несложной, поэтому я не привожу ее полного решения. Алгоритмические же замечания будут совсем не лишними. Итак, предположим, что исходный файл состоит из строк, в каждой из которых записан набор атрибутов (Aj, А2,А) и сопоставленное ему значение V. Предположим, атрибут А может принимать одно из значений (так, атрибут время года из примера может принимать одно из четырёх значений - зима , весна , лето или осень ).
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |