
|
|
Программирование >> Oracle
чом; она будет перемещаться лишь при изменении размера и структуры самого индекса. Чтобы справиться с этой проблемой, сервер Oracle поддерживает логические идентификаторы строк. Эти логические идентификаторы строк основаны на первичном ключе таблицы, организованной по индексу. Они также могут включать подсказку о текущем местонахождении строки (хотя через некоторое время эта подсказка становится неверной, поскольку данные в организованной по индексу таблице перемещаются). Индекс по таблице, организованной по индексу, менее эффективен, чем по обтчной таблице. Доступ по индексу к обычной таблице обычно требует ввода/вывода для просмотра структуры индекса, а затем одного чтения данных таблицы. В случае таблицы, организованной по индексу, обычно выполняется два просмотра: по структуре вторичного индекса и по самой таблице. Поэтому индексы по таблицам, организованным по индексу, обеспечивают достаточно быстрый и эффективный доступ к данным в столбцах, не входящих в первичный ключ. Итак, при использовании таблиц, организованных по индексу, важнее всего выбрать правильное сочетание данных, хранящихся в блоках индекса, и данных, хранящихся в сегменте остатка. Проверьте различные варианты с разными условиями попадания столбцов в сегмент остатка. Определите, как они влияют на выполнение операторов INSERT, UPDATE, DELETE и SELECT. Если таблица заполняется данными один раз и часто читается, поместите в блок индекса как можно больше данных. Если таблица часто изменяется, решите, что для вас лучше: поместить все данные в блок индекса (что хорошо для чтения) или часто реорганизовывать данные индекса (что плохо для изменений). То, что было сказано относительно списков FREELIST для обычных таблиц, относится и к таблицам, организованным по индексу. Параметры PCTFREE и PCTUSED для таблиц, организованных по индексу, имеют два назначения. Для таблицы, организованной по индексу, параметр PCTFREE не имеет такого значения, как для обычной таблицы, а параметр PCTUSED для нее вообще не используется. При создании сегмента OVERFLOW, однако, параметры PCTFREE и PCTUSED интерпретируются точно так же, как и для таблицы, организованной в виде кучи; их надо устанавливать для дополнительного сегмента, исходя из тех же соображений, что и для обычной таблицы. Таблицы в индексном кластере Я часто сталкиваюсь с тем, что кластеры в СУБД Oracle понимают неправильно. Многие путают их с кластерным индексом СУБД SQL Server или Sybase. Кластеры не имеют с ним ничего общего. Кластер - это способ хранения группы таблиц, имеющих один или несколько общих столбцов, в одних и тех же блоках базы данных, так что взаимосвязанные данные хранятся в одном блоке. Кластерный индекс в СУБД SQL Server позволяет хранить отсортированные по ключу индекса строки; он аналогичен описанной выше организации таблицы по индексу в Oracle. При использовании кластера блок данных может содержать данные из нескольких таблиц. По сути данные хранятся предварительно соединенными . В кластер можно помещать и одну таблицу. При этом хранятся сгруппированные по значению некоторого столбца данные. Например, информация обо всех сотрудниках отдела 10 будет храниться в одном блоке (или в минимально возможном количестве блоков, если все записи в один блок не помещаются). Речь не идет о хранении отсортированных данных - для этого применяется таблица, организованная по индексу. Это хранение кластеризованных по некоторому ключу данных, но в виде кучи. Поэтому строки для сотрудников отдела 100 могут находиться рядом со строками для отдела 1 и очень далеко (физически на диске) от строк для отделов 101 и 99. Графически можно представить кластер так, как показано ниже. Слева мы используем обычные таблицы. Таблица ЕМР хранится в своем сегменте, а таблица DEPT - в своем. Они могут оказаться в разных файлах, в разных табличных пространствах и уж точно - в отдельных экстентах. Справа показано, что произойдет при кластеризации этих двух таблиц. Квадраты представляют блоки базы данных. Значение 10 теперь фак-торизовано и хранится один раз. Все данные из всех таблиц кластера для отдела 10 хранятся в том же блоке. Если все данные для отдела 10 не помещаются в один блок, к исходному блоку будут присоединены дополнительные блоки для размещения остатка, во многом аналогично дополнительным блокам таблиц, организованных по индексу: 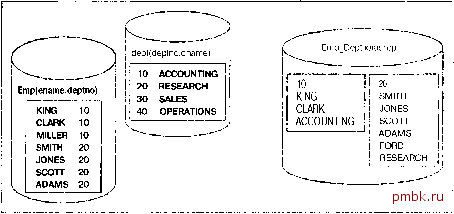 Давайте разберемся, как создать кластеризованный объект. Создать кластер таблиц просто. Параметры хранения (PCTFREE, PCTUSED, INITIAL и т.д.) задаются для кластера, а не для таблиц. В этом есть смысл, поскольку в кластере будет много таблиц, и их строки будут в одном блоке. Разные значения параметра PCTFREE не имеют смысла. Поэтому оператор CREATE CLUSTER аналогичен оператору CREATE TABLE с небольшим количеством столбцов (указываются только столбцы ключа кластера): tkyte@TKYTE816> create cluster emp dept cluster 2 (deptno number(2)) 3 size 1024 Cluster created. Здесь мы создали индексный кластер (есть еще хеш-кластеры; мы рассмотрим их далее). Кластеризующим столбцом для этого кластера будет столбец DEPTNO. Столбцы в таблицах не обязательно должны называться DEPTNO, но они должны быть типа NUMBER(2), чтобы соответствовать определению. В определении кластера я указал опцию SIZE 1024. Она сообщает серверу Oracle, что с каждым значением кластерного клю- ча предположительно будет связано 1024 байт данных. Сервер Oracle будет использовать это для вычисления максимального количества кластерных ключей, которые могут поместиться в блок. При использовании блоков размером 8 Кбайт сервер Oracle будет помешать в блок до семи ключей кластера (но, может, и меньше, если данных окажется больше, чем ожидалось). Другими словами, данные для отделов 10, 20, 30, 40, 50, 60, 70 скорее всего попадут в один блок, а при вставке данных для отдела 80 будет использован новый блок. Это не означает, что хранятся отсортированные данные - просто, если данные об отделах будут вставляться в таком порядке, они, естественно, будут храниться вместе. Если вставлять данные по отделам в следующем порядке: 10, 80, 20, 30, 40, 50, 60, а затем - 70, то последний отдел, 70, окажется в новом блоке. Как будет показано ниже, на количество хранящихся в блоке ключей влияет как размер данных, так и порядок их вставки. Параметр SIZE, таким образом, контролирует максимальное количество ключей кластера в блоке. Он оказывает максимальное влияние на использование пространства в кластере. При установке слишком большого значения в блоке окажется очень мало ключей, и будет использоваться больше пространства, чем необходимо. Если значение слишком маленькое, данные будут слишком сильно фрагментированы, что противоречит цели создания кластера - хранить все данные вместе, в одном блоке. Это - один из важней ших параметров для кластера. Теперь перейдем к созданию индекса кластера. Индекс кластера должен быть создан до того, как в него начнут поступать данные. Можно создавать таблицы в кластере прямо сейчас, но я собираюсь одновременно создавать таблицы и наполнять их данными, а индекс кластера должен быть создан до вставки в него каких-либо данных. Задача индекса кластера - брать значение ключа кластера и возвращать адрес блока, содержащего это значение. Фактически это первичный ключ, в котором каждое значение ключа кластера указывает на один блок в самом кластере. Так что при запросе данных для отдела 10 сервер Oracle прочитает ключ кластера, определит адрес блока для этого ключа, а затем будет читать данные. Индекс по ключу кластера создается следующим образом: tkyte@TKYTE816> create index emp dept cluster idx 2 on cluster emp dept cluster Index created. При этом можно задавать все обычные параметры хранения индекса и помещать его в другое табличное пространство. Это самый обычный индекс, который просто индексирует ключи кластера и может также иметь отдельную запись для пустого значения (почему это существенно, см. в главе 7, посвященной индексам). Теперь все готово для создания таблиц в кластере: tkyte@TKYTE816> create table dept 2 (deptno number(2) primary key, 3 dname varchar2 (14) , 4 loc varchar2(13) 6 cluster einp dept cluster (deptno)
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |