
|
|
Программирование >> Oracle
1136 Глава 14 tkyte@TKYTE816> update range example 2 set range key column = range key column+366 update range example * ERROR at line 1: OBA-14402: updating partition key column would cause a partition change Сразу же выдается сообщение об ошибке. В Oracle 8.1.5 и более новых версиях можно включить поддержку переноса строк для таблицы, что позволит перемещать строку из одного фрагмента в другой. В версиях Oracle 8.0 это было невозможно; приходилось удалять строку и повторно вставлять ее с измененными значениями. Следует, однако, помнить о побочном эффекте перемещения строк. Это - один из двух случаев, когда идентификатор строки (ROWID) изменяется при изменении данных (другой - изменение первичного ключа таблицы, организованной по индексу; универсальный идентификатор для этой строки тоже изменится): tkyte@TKYTE816> select rowid from range example 2 / ROWID AAAHeRAAGAAAAAKAAA tkyte@TKYTE816> alter table range example enable row movement 2 / Table altered. tkyte@TKYTE816>updaterange example 2 set range key column = range key column+366 1 row updated. tkyte@TKYTE816> select rowid from range example 2 / ROWID AAAHeSAAGAAAABKAAA Итак, если учитывать изменение идентификатора строки при изменении значения ключа фрагментации, включение перемещения строк позволит изменять эти ключи. Следующий пример демонстрирует фрагментацию таблицы по хеш-функции. В этом случае сервер Oracle будет применять хеш-функцию к ключу фрагментации для определения того, в какой из N фрагментов надо поместить данные. Для наиболее равномерного распределения рекомендуется в качестве значения N использовать степени двойки (2, 4, 8, 16 и т.д.). Фрагментация по хеш-функции предназначена для равномерного распределения данных по нескольким устройствам (дискам). В качестве хеш-ключа для таблицы необходимо выбирать столбец или набор столбцов с как можно большим количеством уникальных значений - это обеспечивает равномерное распределение значений. Если выбрать столбец, имеющий всего четыре значения, и использовать два Фрагментация 1137 фрагмента, в результате хеширования все строки могут оказаться в одном фрагменте, что делает фрагментацию бессмысленной. Создадим таблицу, распределенную по хеш-функции на два фрагмента: tkyte@TKYTE816> CREATE TABLE hashexample date, varchar2(20) 2 (hash key column 3 data 5 PARTITION BY HASH (hash key column) 6 (partition part l tablespace p1, 7 partition part 2 tablespace p2 Table created. Следующая схема показывает, что сервер Oracle применит хеш-функцию к столбцу HASH KEY COLUMN и, в зависимости от ее значения, вставит строку в один из двух фрагментов:  Теперь рассмотрим пример смешанной фрагментации, когда строки фрагментируются и по диапазону, и по хеш-функции. Здесь фрагментация по диапазону будет выполняться для одного набора столбцов, а фрагментация по хеш-функции - для другого. Вполне допустимо использовать одни и те же столбцы в обоих условиях фрагментации: tkyte@TKE816> CREATE 2 3 4 10 11 12 (range key column hash key column data TLE compositeexample date, int, varchar2(20) PARTITION BY RANGE (range key column) subpartition by hash(hash key column) subpartitions 2 PARTITION part l VALUES LESS THAN(to date(01-jan-199 5,dd-mon-yyyy)) (subpartition part l sub 1, subpartition part l sub 2 1138 Глава 14 14 15 18 19 20 PARTITION part 2 VALUES LESS THAN(to date(01-jan-19 9 6,dd-mon-yyyy)) (subpartition part 2 sub 1, subpartition part 2 sub 2 Table created. При смешанной фрагментации сервер Oracle сначала применяет правила фрагментации по диапазону, чтобы понять, к какому диапазону относятся данные, а затем -хеш-функцию, которая и определяет, в какой физический фрагмент попадет строка: 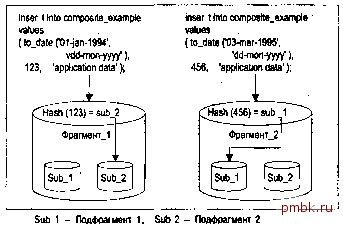 Фрагментация по диапазону используется, когда данные логически разделяются по значениям. Классический пример - данные, привязанные к периоду времени. Фрагментация по кварталам, по финансовым годам, по месяцам. Фрагментация по диапазону во многих случаях позволяет пропускать фрагменты, в том числе для условий строгого равенства и условий, задающих диапазоны: меньше, больше, в указанных пределах и т.д. Фрагментация по хеш-функции подходит для данных, в которых не удается выделить естественные диапазоны значений, подходящие для фрагментации. Предположим, необходимо загрузить в таблицу данные переписи населения - в них может и не быть атрибута, по которому имеет смысл разделять данные на диапазоны. Однако хотелось бы воспользоваться преимуществами, которые предоставляет фрагментация с точки зрения администрирования, производительности и доступности данных. Можно выбрать набор столбцов с уникальными значениями, по которым выполнять хеширование. Это позволит равномерно распределить данные по любому количеству фрагментов. Игнорирование фрагмента для объектов, разделенных по хеш-функции, возможно только для условий строгого равенства или IN (значение 1, значение2,...), но не для условий, задающих диапазоны значений. Составная фрагментация подходит, когда данные логически поделены на диапазоны, но получающиеся в результате фрагменты - слишком большие, чтобы ими можно
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |