
|
|
Программирование >> Oracle
Фрагментация 1133 теперь надо просматривать 5, 10 или 20 маленьких. Более детально мы изучим это позже, при рассмотрении типов фрагментации индексов. Имеется возможность повысить эффективность работы системы ООТ с помощью фрагментации, например, повышая степень параллелизма за счет уменьшения количества конфликтов. Фрагментацию можно использовать для распределения изменений одной таблицы по нескольким физическим фрагментам. Вместо использования одного сегмента таблицы и одного сегмента индекса можно создать 20 фрагментов таблицы и 20 фрагментов индекса. Результат будет таким же, как при наличии 20 таблиц вместо одной, - конфликтов при изменениях этого разделяемого ресурса станет меньше. Что касается распараллеливания запросов, то оно, как я уже подчеркивал ранее, в среде ООТ нежелательно. Распараллеливание операций имеет смысл оставить администратору базы данных для пересоздания и создания индексов, анализа таблиц и т.п. Для запросов в системе ООТ обычно характерен очень быстрый доступом к данным по индексу, так что фрагментация не слишком ускорит этот доступ. Это не означает, что следует вообще отказаться от использования фрагментации в среде ООТ, просто не стоит ожидать существенного повышения производительности только за счет фрагментации объектов. Приложения в данном случае не могут использовать преимущества, которые могла бы дать фрагментация. В среде же хранилища данных/систем поддержки принятия решений (СППР) фрагментация не только существенно упрощает администрирование, но и позволяет ускорить работу. Предположим, имеется большая таблица, к которой надо выполнить запрос, анализирующий продажи по кварталам. Для каждого квартала имеются сотни тысяч записей, а общее количество записей измеряется миллионами. Итак, необходимо запросить сравнительно небольшой срез общего набора данных, но индексировать данные по кварталам нет смысла. Такой индекс будет ссылаться на сотни тысяч записей для каждого квартала, и просмотр индекса по диапазону при этом будет выполняться чрез-в1чайно медленно (подробнее об этом см. в главе 7, посвященной индексам). Итак, для выполнения большого количества запросов приходится полностью просматривать таблицу, но при этом просматриваются миллионы записей, большинство из которых не связаны с выполняемым запросом. Используя соответствующую схему фрагментации, можно разделить данные по кварталам таким образом, что при запросе данных за конкретный квартал полностью просматривать придется только один фрагмент. Это лучшее из всех возможных решений. Кроме того, в среде хранилищ данных/систем поддержки принятия решений часто используется распараллеливание запросов. Здесь операции типа параллельного просмотра индексов по диапазону или параллельный, быстрый полный просмотр индекса не только имеют смысл, но и дают преимущества. Мы хотим максимально использовать все имеющиеся ресурсы, и распараллеливание запросов позволяет этого добиться. Так что, в подобной среде фрагментация с большой долей вероятности ускорит выполнение запросов. Упорядочив преимущества фрагментации по степени важности, получим: 1. Увеличение доступности данных - хорошо для всех типов систем. 2. Упрощение администрирования больших объектов базы данных за счет замены их несколькими меньшими - хорошо для всех типов систем. 1134 Глава 14 3. Повышение производительности некоторых операторов ЯМД и запросов - достигается, в основном, в среде больших хранилищ данных. 4. Уменьшение количества конфликтов в системах ООТ с большим количеством вставок (например, в таблицу записей аудита) за счет их распределения по нескольким отдельным фрагментам (распределение горячей точки по нескольким дискам). Как выполняется фрагментация В этом разделе будут рассмотрены схемы фрагментации, предлагаемые сервером Oracle 8i. Имеется три схемы фрагментации для таблиц и две - для индексов. В рамках двух схем фрагментации индексов можно выделить несколько классов фрагментирован-ных индексов. Мы рассмотрим преимущества и отличительные особенности каждого класса, а также разберемся, какие схемы фрагментации следует применять для различных типов приложений. Схемы фрагментации таблиц В настоящее время сервер Oracle поддерживает три способа фрагментации таблиц. Фрагментация по диапазону. Можно указать диапазоны значений данных, строки для которых должны храниться вместе. Например, все данные за январь 2001 года будут храниться в фрагменте 1, все данные за февраль 2001 года - в фрагменте 2 и т.д. Это, вероятно, самый популярный способ фрагментации в Oracle Фрагментация по хеш-функции. Такая схема уже использовалась в первом примере этой главы. К значению одного или нескольких столбцов применяется хеш-функция, определяющая фрагмент, в который помещается строка. Составная фрагментация. Это сочетание фрагментации по диапазону и по хеш-функции. Можно сначала применить разбиение по диапазону значений данных, а затем выбрать в пределах диапазона фрагмент на основе значения хеш-функции. Следующий код и схемы наглядно демонстрируют применение этих способов фрагментации. Кроме того, операторы CREATE TABLE структурированы так, чтобы можно было понять синтаксис создания фрагментированной таблицы. Сначала рассмотрим таблицу, фрагментированную по диапазону: tkyte@TKYTE816> CREATE TABLE range example 2 (range key column date, 3 data varchar2(20) 5 PARTITION BY RANGE (range key column) 6 (PARTITION part l VALUES LESS THAN 7 (to date(01-jan-1995,dd-mon-yyyy)), 8 PARTITION part 2 VALUES LESS THAN 9 (to date(01-jan-1996, dd-mon-yyyy)) Фрагментация 1135 10 ) 11 / Table created. Следующая схема показывает, что сервер Oracle проверяет столбец RANGE KEY COLUMN и в зависимости от его значения вставляет строку в один из фрагментов: 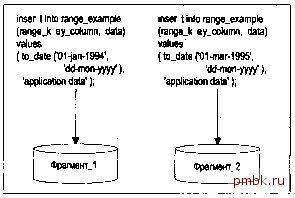 Интересно, что произойдет, если изменится значение столбца, определяющего, в какой фрагмент попадает строка. При этом надо учитывать два случая. Изменение не перемещает строку в другой фрагмент; строка принадлежит тому же фрагменту. Такое изменение возможно всегда. Изменение вызывает перемещение строки в другой фрагмент. Такое изменение поддерживается, только если для таблицы включен перенос строк, иначе выдается сообщение об ошибке. Эту особенность легко продемонстрировать. Вставим строку во фрагмент PART 1 созданной ранее таблицы. Затем изменим значение столбца RANGE KEY COLUMN так, что строка останется во фрагменте PART 1, - это изменение будет успешно выполнено. Далее изменим значение столбца RANGE KEY COLUMN так, чтобы переместить строку во фрагмент PART 2. При этом будет выдано сообщение об ошибке, поскольку перенос строк явно включен не б1л. Наконец, изменим таблицу, разрешив перемещение строк, и продемонстрируем последствия этого изменения: tkyte@TKYTE816> insert into rangeexanple 2 values (to date(01-jan-1994, dd-mon-yyyy), application data),- 1 row created. tkyte@TKYTE816> update rangeexample 2 set range key column = range key column+l 1 row updated. Как и ожидалось, изменение успешно выполнено, ведь строка осталась во фрагменте PART 1. Затем посмотрим, что произойдет, если изменение вызывает перемещение строки:
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |