
|
|
Программирование >> Oracle
Индексы на основе В*-дерева Индексы на основе В*-дерева, или, как я их назвал, обычные индексы, - наиболее широко используемый тип индексной структуры в базе данных. По реализации они Индексы по уб1ванию. Далее индексы по убыванию не будут втделяться как отдельный тип. Однако поскольку они только появились в Oracle 8i, то заслуживают отдельного рассмотрения. Индексы по убыванию позволяют отсортировать данные в структуре индекса от больших к меньшим (по убыванию), а не от меньших к большим (по возрастанию). Мы разберемся, почему это важно и как такие индексы работают. Индексы на основе битов1х карт. Обгчно в В*-дереве имеется однозначное соответствие между записью индекса и строкой - запись индекса указывает на строку. В индексе на основе битовых карт запись использует битовую карту для ссылки на большое количество строк одновременно. Такие индексы подходят для данных с небольшим количеством различных значений, которые обычно только читаются. Столбец, имеющий всего три значения - Y, N и NULL, - в таблице с миллионом строк очень хорошо подходит для создания индекса на основе битовых карт. Индексы на основе битовых карт не нужно использовать в базе данных класса ООТ из-за возможных проблем с одновременным доступом (которые мы рассмотрим далее). Индексы по функции. Эти индексы на основе В*-дерева или битовых карт хранят вычисленный результат применения функции к столбцу или столбцам строки, а не сами данные строки. Это можно использовать для ускорения выполнения запросов вида: SELECT * FROM T WHERE ФУНКЦИЯ(СТОЛБЕЦ) = НЕКОТО-РОЕ ЗНАЧЕНИЕ, поскольку значение ФУНКЦИЯ(СТОЛБЕЦ) уже вычислено и хранится в индексе. Прикладн1е (application domain) индексы. Это индексы, которые строит и хранит приложение, будь-то в базе данных Oracle или даже вне базы данных Oracle. Надо сообщить оптимизатору, насколько избирателен индекс, насколько дорогостояще его использование, а оптимизатор решает на основе этой информации, использовать этот индекс или нет. Текстовый индекс interMedia - пример прикладного индекса; он построен с помощью тех же средств, которые можно использовать для создания собственных прикладных индексов. Текстовые индексы interMedia. Это встроенные в сервер Oracle специализирован- ные индексы для обеспечения поиска ключевых слов в текстах большого объема. Описание этих индексов будет представлено в главе 17, посвященной компоненту interMedia. Как видите, предлагается несколько типов индексов на выбор. В следующих разделах я хочу представить технические детали их работы и порекомендовать, когда их использовать. Еще раз подчеркну: мы не будем рассматривать ряд вопросов, интересующих администраторов баз данных (например, механизм оперативной перестройки индекса), а сосредоточимся на практическом использовании индексов в приложениях. подобны двоичному дереву поиска. Цель их создания - минимизировать время поиска данных сервером Oracle. При наличии индекса по числовому столбцу, структура индекса может выглядеть так: 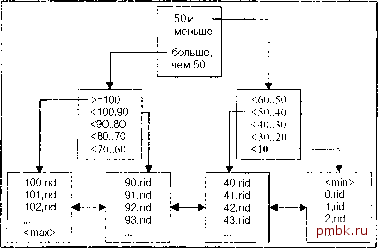 Блоки самого нижнего уровня в индексе, которые называют листовыми вершинами, содержат все проиндексированные ключи и идентификаторы строк (rid на схеме), ссылающиеся на соответствующие строки. Промежуточные блоки над листовыми вершинами называют блоками ветвления. Они используются для переходов по структуре. Например, если необходимо найти в индексе значение 42, надо начать с вершины дерева и двигаться вправо. При проверке этого блока оказывается, что необходимо перейти к блоку в диапазоне от 40 до 50 . Этот блок оказывается листовым и ссылается на строки, содержащие число 42. Интересно отметить, что листовые блоки фактически образуют двухсвязный список. Как только найдено начало среди листовых вершин, т.е. первое значение, очень легко просматривать значения по порядку (это называют также просмотром диапазона по индексу, index range scan). Проходить по структуре индекса бол ше не нужно; мы просто переходим по листовым вершинам. Это существенно упрощает поиск строк но условиям следующего вида: where x between 20 and 30 Сервер Oracle находит первый блок индекса, содержащий значение 20, а затем проходит по двухсвязному списку листовых вершин, пока не обнаружит значение больше 30. На самом деле такой структуры, как неуникальный индекс на основе В*-дерева, нет. В неуникальном индексе сервер Oracle просто добавляет идентификаторы строк к ю-чу индекса, что и делает его неуникальным. В неуникальном индексе данные хранятся отсортированными сначала по значению ключа индекса (в порядке, задаваемом ключом индекса), а потом - по идентификатору строки. В уникальном индексе данные отсортированы только по значению ключа индекса. Одно из свойств В*-дерева состоит в том, что все листовые блоки должны быть на одном уровне, если точнее, разница по высоте между ветвями дерева не может быть больше 1. Уровень листов1х блоков называют также высотой дерева. Все вершины выше листов1х могут указывать только на содержащие более детальную информацию вершины следующего уровня, а листовые вершины указывают на конкретные идентификаторы строк или диапазоны идентификаторов строк. Большинство индексов на основе В*-де-рева будут иметь высоту 2 или 3, даже для миллионов записей. Это означает, что для поиска ключа в индексе потребуется 2 или 3 чтения, что неплохо. Еще одно свойство - автоматическая балансировка листовых вершин: они почти всегда располагаются на одном уровне. Есть причины, по которым индекс может оказаться не идеально сбалан-сированн1м при изменении и удалении записей. Сервер Oracle будет пытаться заполнять блоки индекса не более чем на три четверти, но и это свойство может временно нарушаться при выполнении операторов DELETE и UPDATE. В общем случае В*-де-рево - отличный универсальный механизм индексирования, хорошо работающий как в случае больших, так и маленьких таблиц, и лишь немного хуже работающий при росте базовой таблицы, если только дерево остается сбалансированным. Интересно, что индексы на основе В*-дерева можно сжимать . Это не такое сжатие, как в zip-файлах; при сжатии удаляется избыточность в составных индексах. Мы рассматривали этот механизм в разделе Таблицы, организованные по индексу главы 6, но вернемся к нему еще раз. В основе сжатия ключа индекса лежит разбиение записи на две части: префикс и суффикс. Префикс строится по начальным столбцам составного индекса, и его значения часто повторяются. Суффикс - это завершающие столбцы ключа индекса, и эта часть в записях индекса с одинаковым префиксом - уникальна. Давайте создадим таблицу и индекс, и определим используемое им пространство без сжатия, а затем пересоздадим индекс с включенным сжатием, и оценим разницу. В этом примере используется процедура showspace, представленная в главе 6. tkyte@TKYTE816> create table t 2 as 3 select * from all objects Table created. tkyte@TKYTE816> create index t idx on 2 t(owner,object type,object name) ; Index created. tkyte@TKYTE816> tkyte@TKYTE816> exec show space(T IDX,user,INDEX) Free Blocks......................0 Total Blocks.....................192 Total Bytes......................1572864 Unused Blocks....................35 Unused Bytes.....................286720 Last Used Ext FileId............6 Last Used Ext BlockId...........649 Last Used Block..................29 PL/SQL procedure successfully completed.
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |