
|
|
Программирование >> Создание клиентов mysql
Концепции распределенных баз данных 513 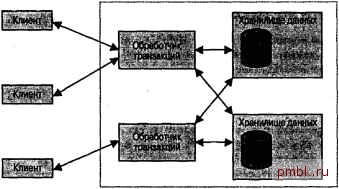 Рис. 29.2. Распределенные серверы В идеале клиенты не знают, является система распределенной или нет. Они лишь посылают ей запросы, а система возвращает клиентам результаты этих запросов. Как она это делает, клиентов не интересует. На практике распределенные базы данных проявляют разную прозрачность . В крайнем случае РБД хранится на нескольких независимых серверах, а клиентскому приложению приходится выбирать сервер в зависимости от того, какую информацию требуется получить. Это подразумевает, что таблицы, находящиеся на разных серверах, не имеют никаких внутренних связей. Естественно, такая организация РБД лишь изредка оказывается полезной. Система управления распределенными базами данных, или РСУБД, предоставляет клиентам унифицированный интерфейс доступа к данным, благодаря которому возникает иллюзия единого сервера. Если данные находятся в разнтх местах, РСУБД пос1ла-ет запросы и обновления в соответствующие хранилища. В зависимости от того, с каким хранилищем ведется работа, производительность системы может оказаться разной, но, по крайней мере, клиентам не приходится самим заниматься выбором сервера. Если данные реплицируются между несколькими серверами, клиент в общем случае может предпочесть тот или иной сервер. В подобной схеме все серверы хранят одни и те же данные. Специальный модуль может помогать клиентам в выборе серверов, осуществляя выравнивание нагрузки. РСУБД отвечает за выполнение транзакций в многосерверной среде, но в любой момент времени два сервера не могут быть синхронизированы между собой. В РБД применяется несколько схем распределения данных. В случае репликации каждый сервер хранит весь объем данных. Для этого требуется, чтобы РСУБД дублировала транзакции, позволяя всем клиентам видеть согласованный образ базы данных. В случае несимметричного разделения данных выбирается уровень сегментации. На самом высоком уровне расщеплению подвергаются отдельные базы данных, но не таблицы. Каждая таблица целиком находится в каком-то одном месте. На более низком уровне таблицы расщепляются по строкам или столбцам. Например, при горизонтальном расщеплении отдельные подмножества записей помещаются в разные хранилища, а при вертикальном расщеплении подмножества формируются на основании столбцов. Отложенная синхронизация Создать точную копию базы данных MySQL довольно просто. Способы резервного копирования баз данных описывались в главе 25, Устранение последствий катастроф . Что касается восстановления данных, то это можно сделать на любом сервере. Располагая такими средствами, несложно реализовать распределенную базу данных, которая синхронизируется через достаточно большие промежутки времени, например раз в день. Рассмотрим проблему обновления данных. Если обновления происходят сразу на двух серверах, их нужно согласовывать. Чтобы не возникали неразрешимые ситуации, необходимо позволить вносить изменения только на одном сервере. Тогда синхронизация будет заключаться в дублировании содержимого сервера, доступного для записи, на все остальные серверы. Их полезность зависит от того, насколько важна актуальность данных. Во многих случаях база данных, содержащая все записи, кроме тех, которые были созданы за последние 24 часа, вполнеприемлема. Методика отложенной синхронизации идеально подходит дя баз данных, содержащих результаты ночных отчетов. Например, Web-узел, предоставляющий доступ к может регистрировать названия запрашиваемых песен и составлять рейтинги популярности. Раз в день все серверы посылают свои журнальные главному серверу, который корректирует рейтинги согласно новой статистике. Схема такой базы данных приведена в листинге Листинг 29.1. ISiXBMiijajfn/ieiViw /* Каталог МРЗ-файлов. */ CREATE TABLE song ( ID INT NOT NULL AUTO INCREMENT, Name CHAR (4 0) NOT NULL, Artist CHAR (16) NOT NULL, Filename CHAR (80) NOT NULL, PRIMARY KEY (ID) , INDEX (Name), INDEX (Artist) /* Журнал запрашиваемых файлов, */ CREATE TABLE log ( Server TINYINT UNSIGNED NOT NULL, Song INT NOT NULL, DownloadTime DATETIME NOT NULL Каждый сервер хранит информацию о доступных песнях в таблице song. В таблицу log заносится запись всякий раз, когда кто-то загружает очередной У этой таблицы нет первичного ключа, так как в обычном режиме она используется лишь для вставкизаписей. Наличие индекса только замедлит работу с таблицей. Раз в день таблицы log всех серверов объединяются по следующему сценарию. Один из серверов прекращает обслуживать запросы Web-приложений. Остальные серверы создают копии таблицы log, извлекают из них последние записи и посылают Отложенная синхронизация их серверу, генерирующему отчет. На время этой процедуры каждый сервер должен заблокировать свою таблицу log. Чтобы слишком много пользовательских запросов не оказалось заблокировано, процедуру желательно выполнять в период минимальной активностисервера. Сервер, генерирующий отчет, загружает полученные данные в свою таблицу log, после чеговыполняет сценарий, показанный в листинге 29.2. В этом сценарии создаются два рейтинга популярности: по всем песням и за последние 24 часа. Временный индекс таблицы log ускоряет ее просмотр. /* Создание индекса. */ CREATE INDEX song ON log (Song) ; /* Определение рейтинга всех песен. */ DROP TABLE IF EXISTS popular alltime; CREATE TABLE popular alItime ( Rank INT NOT NULL, Song INT NOT NULL, Hits INT NOT NULL SET ©id = 0; INSERT INTO popular alltime SELECT {@id := @id+l). Song, COUNT(*) FROM log GROUP BY 2 ORDER BY 3 DESC; ALTER TABLE popular alItime ADD PRIMARY KEY(Rank); /* Определение рейтинга песен за последние 24 часа. */ DROP TABLE IF EXISTS popular last24; CREATE TABLE popular last24 ( Rank INT NOT NULL, Song INT NOT NULL, Hits INT NOT NULL SET @id = 0; INSERT INTO popular last24 SELECT (@id :=@id+l), Song, COUNT(*) FROM log WHERE DownloadTime > DATE SUB(NOW(), INTERVAL 2 4 HOUR) GROUP BY 2 ORDER BY 3 DESC; ALTER TABLE popular last24 ADD PRIMARY KEY (Rank); /* Удаление Kca. */ DROP INDEX song ON log;
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |