
|
|
Программирование >> Создание клиентов mysql
РАСПРЕДЕЛЕННЫЕ БАЗЫ ДАННГХ В этой главе... Концепции распределенных баз данных Отложенная синхронизация Репликация в MySQL Запуск нескольких серверов   этой главе рассматриваются концепции распределенных баз данных. Такие базы данных хранятся и обрабатываются на нескольких компьютерах, что повышает их производительность, доступность и устойчивость к сбоям. Чтобы все компьютеры оставались синхронизированными, посети должны рассылаться обновления. В идеальной ситуации распределенная база данных выглядит для клиентов как единый, монолитный сервер. В MySQL поддерживаетсярепликация данных, что позволяет запускать несколько серверов, синхронизирующих свои базы данных. Сервер может быть главным, подчиненным или и тем идругим одновременно. Главный сервер фиксирует все изменения и делает их доступными для одного или нескольких подчиненных серверов. Последние, в свою очередь, запрашивают обновления у одного главного сервера. В этой главе рассказывается также о том, как запустить несколько серверов MySQL на одном компьютере. Данная методика позволяет повысить безопасность серверов, которые работают в многопользовательском режиме. Концепции распределенных баз данных Обычный сервер хранит у себя все данные и обслуживает все клиентские запросы. Схема взаимодействия между сервером и клиентами изображена на рис. Сервер данные располагаются на одном или нескольких физических дисках. Чтобы сделать запрос, клиент устанавливает соединение с сервером. Сервер анализирует инструкции, выполняем их, извлекает данные и возвращает результаты запроса. По мере возрастания нагрузки производительность сервера снижается. Чтобы избежать этого, задействуют дополнительные ресурсы, например наращивают память, ставят дополнительные процессоры и даже сетевые платы. Это эффективная стратегия, если клиенты расположены в непосредственной близости от сервера, например нескольк еров приложений взаимодействуют с одной СУБД. Но в тех архитек* турах, где сервер и клиенты удалены друг от друга, производительность обратно порциональна расстоянию. 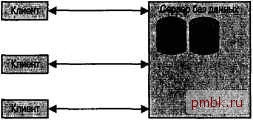 Рис Обычный сервер баз данных Решением этой проблемы являются распределенные базы данные №Д), которые сегментируют хранимую информацию и перемещают отдельные ее блоки ближе к нужным клиентам. Способов организации таких баз данных много. Можно разместить таблицы на разных компьютерах или использовать несколько идентичных хранилищ. Во втором случае серверы взаимодействуют друг с другом для поддержания синхронизации. Если на одном изсерверов происходит обновление данных, оно распространяется и на все остальные серверы. К недостаткам распределенных баз данных можно отнести то, что возрастает сложность управления ими. Но преимуществ все же больше. Главное из них- повышение производительности. Данные быстрее обрабатываются несколькими серверами, а кроме того, данные располагаются ближе к тем пользователям, которые чаще с ними работают. Система становится более устойчивой, если она способна выдержать сбой одного из своих компонентов. В распределенной базе данных с симметричной схемой хранения исчезновение одного из серверов приводит к замедлению работы пользователей, находящихся ближе к этому серверу, но в целом система остается работоспособной. К тому же, она легко масштабируется, так как ее не нужно останавливать при добавлении еще одного сервера. В несимметричной системе можно оптимизировать схему расположения данных. Чем ближе пользователи находятся к нужным им данным, тем меньше на ихработу влияют сетевые задержки. В результате серверам приходится обрабатывать меньшие объемы данных. Это также способствует повышению безопасности данных, поскольку их можно физически хранить в тех системах, где пользователи имеют право работать с соответствующими данными. В целом, однако, применение распределенных баз данных связано с достаточно высоким риском. Требуется обеспечить соблюдение мер безопасности сразу на нескольких узлах, что не так-то просто реализовать. Распределенные базы данных трудно проектировать и обслуживать. Порядок работы в системе может со временем поменяться, что повлечет за собой изменение схемы хранения данных. Как клиенты, так и серверы должны уметь обрабатывать запросы к даннхм, которые не расположена: в ближайшей системе. Плохо спроектированная РБД может демонстрировать меньшую производительность, чем одиночный сервер. РБД состоит из трех основн частей: клиентов, модуля обработки транзакций и хранилища данных. Сервер обычно берет на себя задачи обработки транзакций и хранения данных, хотя в полностью распределенной базе данных за решение этих задач отвечают разные аппаратные компоненты. Обратимся к рис. 29.2. Здесь три клиента взаимодействуют с двумя модулями обработки транзакций, которые, в свою очередь, работают с двумя хранилищами. Клиенты посылают свои запросы модулям, а те определяют, в каком из хранилищ находятся требуемые данные.
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |