
|
|
Программирование >> Программирование баз данных
Проводя сравнение некластеризованных индексов, заданных на неупорядоченной таблице, с кластеризованными индексами, ради справедливости необходимо отметить следующее: весьма велики шансы того, что многие считанные страницы будут оставаться в памяти (в кэше) и поэтому выборка других строк, относящихся к этим страницам, будет осуществляться исключительно быстро. Тем не менее и при таких обстоятельствах для выборки данных приходится выполнять несколько дополнительных логических операций. На рис. 8.7 показана такая же процедура поиска, которая выполнялась с помощью кластеризованного индекса (см. рис. 8.3), но на этот раз с использованием некластеризованного индекса, заданного на неупорядоченной таблице. Поиск записей с 158 до 400 Корневой узел 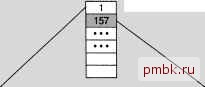 Нелистовой уровень   Листовой уровень
Страницы данных
Puc. 8.7. Процедура поиска с использованием некластеризованного индекса, заданного на неупорядоченной таблице При этом основная часть операций перемещения по индексу осуществляется точно так же, как и в предыдущем примере. Поиск начинается с того же корневого узла, после чего происходит переход вниз по уровням дерева, и в процессе этого перехода каждый раз обнаруживаются страницы, охватывающие все меньшую область представления данньгх, до тех пор, пока не достигается листовой уровень индекса. Различия проявляются только начиная с этого момента. Если используется кластеризованный индекс, то поиск может быть остановлен непосредственно в этом месте, а при использовании некластеризованного индекса приходится выполнять дополнитель-щю работу. Если некластеризованный индекс задан на неупорядоченной таблице, то достаточно перейти на один уровень вниз. Для этого применяется идентификатор строки, полученный на странице индекса листового уровня, затем осуществляется переход к указанной строке, и только после этого достигается возможность обратиться к реальным данным. Некластеризованные индексы, заданные на кластеризованной таблице Если применяются некластеризованные индексы, заданные на кластеризованной таблице, то аналогии с кластеризованными индексами продолжаются, но обнаруживаются и различия. В некластеризованных индексах, заданных на кластеризованной таблице, так же, как и в некластеризованных индексах, заданных на неупорядоченной таблице, уровни индекса, отличные от листовых, во многом напоминают соответствующие уровни кластеризованного индекса. Различия обнаруживаются только после перехода к листовому уровню. На листовом уровне обнаруживаются еще более резкие различия по сравнению с теми, которые обнаруживались между двумя другими индексными структурами, поскольку в индексе рассматриваемого типа для поиска данных применяется еще один индекс. При использовании кластеризованных индексов поем достижения листового уровня обнаруживаются действительные данные. Если применяется некластеризованный индекс, заданный на неупорядоченной таблице, на листовом уровне обнаруживаются не искомые данные, а идентификатор, позволяющий перейти непосредственно к данным (т.е. для достижения данных нужно сделать всего лишь еще один шаг). А что касается некластеризованного индекса, заданного на кластеризованной таблице, то при его использовании на листовом уровне обнаруживается так называемый кластеризованный ключ. Это позволяет получить достаточно информации для того, чтобы продолжить поиск, воспользовавшись кластеризованным индексом. Пример действий, осуществляемых при использовании некластеризованных индексов, заданных на кластеризованной таблице, показан на рис. 8.8. Таким образом, при использовании индекса рассматриваемого типа осуществляются две полностью разные цроцедуры поиска. В примере, приведенном на рис. 8.8, вначале осуществляется поиск в диапазоне. Для этого выполняется один просмотр индекса, что позволяет выполнить выборку данных с помощью некластеризованного индекса для обнаружения непрерывного участка данных, соответствующих применяемому критерию (LIKE Т% ). Просмотр такого рода, который позволяет перейти непосредственно к конкретному участку индекса, называется позиционированием (seek). После этого начинается операция поиска второго типа - поиск с использованием кластеризованного индекса. Такая вторая операция поиска осуществляется с очень высоким быстродействием; единственная проблема заключается в том, что эта операция должна выполняться многократно. Дело в том, что в СУБД SQL Server после осуществления первой операции поиска с помощью индекса формируется список (в котором находятся все имена, начинающиеся с буквы Т ), но этот список логически не согласуется с кластеризованным ключом в виде каких-либо непрерывных участков, поэтому поиск каждой строки с данными должен выполняться отдельно, как показано на рис. 8.9. Вполне очевидно, что в связи с необходимостью дважды выполнять поиск издержки становятся больше, чем в той ситуации, когда есть возможность использовать кластеризованный индекс с самого начала. А для первой операции поиска с помощью индекса (в которой применяется некластеризованный индекс) обычно требуется осуществить лишь немного логических операций чтения. Выполнить выборку идентификаторов служащих EmployeelD по условию FName LIKE Т% Корневой узел
Нелистовой уровень
Листовой уровень
К записям, на которые указывает кластеризованный индекс
Puc. 8.8. Выборка данных с помощью некластеризованного индекса, заданного на кластеризованной таблице Например, если данные хранятся в таблице с длиной строки, равной 1000 байтов, и выполняется операция поиска, аналогичная показанной на рис. 8.9 (скажем, такая операция, которая должна возвратить 5 или 6 строк), то должно потребоваться примерно 8-10 логических операций чтения для получения информации из некластеризованного индекса. Но выполнение этих операций чтения позволяет лишь подготовиться к чтению строк с помощью кластеризованного индекса. На выполнение
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |