
|
|
Программирование >> Программирование баз данных
В том случае, если новая строка должна быть вставлена в средней части индексной стр)тст)ры, происходит обычная операция разбиения страницы. Вторая половина строк перемещается со старой страницы на новую страницу, а новая строка записывается на новую или старую страницу, в зависимости от того, к какой из них она относится. А в том случае, если новая строка логически должна быть добавлена в конце индексной структуры, создается новая страница, но на ней записывается только новая строка (рис. 8.5). Упорядоченная вставка в качестве последней записи в кластерный ключ Должна быть вставлена новая запись, но страница уже заполнена. Однако запись является последней, поэтому вносится на новую страницу, не затрагивая существующих данных Рис. 8.5. Добавление повой строки в конце индексной структуры Переход по дереву Как уже было сказано, в кластеризованных таблицах SQL Server в виде В-дерева хранятся не только индексы, но и данные. Теоретически В-деревья обеспечивают такой способ хранения данных, что под каждой ветвью дерева, исходящей из узла, всегда хранится примерно одинаковый объем информации. На рис. 8.6 приведено графическое представление кластеризованного индекса в виде В-дерева. Вполне очевидно, что по своему виду В-дерево кластеризованного индекса фактически является идентичным В-деревьям более общего типа, которые рассматривались выше в данной главе. На рис. 8.6 показано, как выполняется поиск в диапазоне значений ключа от 158 до 400 (кластеризованные индексы являются наиболее подходящими для вьшолнения этой операции). Для этого достаточно выполнить следующее. Перейти к первой искомой строке, а затем включить в состав обрабатываемых данных все оставшиеся строки на текущей странице. То, что нам потребуется вся оставшаяся часть страницы, можно легко определить, поскольку информация из узла, находящаяся на один уровень выше, позволяет узнать, что потребуются данные из других страниц. Значения ключа в индексе представляют собой упорядоченный список, поэтому можно не сомневаться в том, что эти значения являются последовательными. Таким образом, если на следующей странице имеются строки, которые должны быть включены в область поиска, то тем более должна быть включена оставшаяся Поиск записей с 158 до 400 Корневой узел 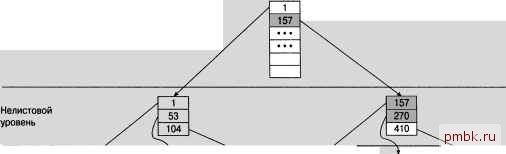 Листовой уровень представляет собой страницу данных
Puc. 8.6. Графическое представление кластеризованного индекса часть текущей страницы. Поэтому мы можем приступить к обработке данных, находящихся на страницах, выявленных в процессе поиска, не задумываясь над тем, нужно ли проверять каждую отдельную строку. Начнем с перехода к корневому узлу. В СУБД SQL Server возможность найти корневой узел обеспечивается благодаря тому, что в системной таблице sys indexes хранится информация об этом узле. Каждому индексу, применяемому в базе данных, соответствует одна строка в таблице sys indexes. Эта системная таблица входит в состав пользовательской базы данных (а не базы данных master). В этой таблице хранится информация о местонахождении всех индексов базы данных и о том, на каких столбцах они основаны. Безусловно, для получения сведений об индексах можно использовать запрос непосредственно к самой этой таблице, но пользователям современных версий СУБД SQL Server настоятельно рекомендуется для выборки необходимых данных из системных таблиц использовать новые системные функции, в этом случае, sys . indexes. Функция sys . indexes возвращает данные в виде таблицы, поэтому к ней можно обращаться как к таблице. Просматривая страницу, соответствующему корневому узлу, можно выяснить, какая следующая страница требует проверки (как показано на рис. 8.6, таковой является вторая страница на втором уровне). После этого процесс поиска продолжается с найденной страницы. По завершении каждого этапа поиска происходит переход ко все более низким уровням дерева, которые охватывают все меньшие и меньшие подмножества данных. Наконец, достигается листовой уровень индекса. В рассматриваемом случае индекс является кластеризованным, поэтому переход на листовой уровень индекса равносилен также достижению требуемой строки (строк) и требуемых данных. Такая особенность кластеризованных индексов, в соответствии с которой полный переход по индексу представляет собой полный переход к искомым данным, является чрезвычайно важной, поскольку способствует значительному повышению производительности. Каковым фактически является это повышение производительности, можно узнать, проведя сравнение с некластеризованными индексами. Разница становится особенно заметной, если некластеризованный индекс создан на основе кластеризованного индекса. Некластеризованные индексы, заданные на неупорядоченной таблице Некластеризованные индексы, заданные на неупорядоченной таблице, во многом аналогичны кластеризованным индексам. Тем не менее между индексами этих двух типов наблюдаются некоторые заметные различия, описанные ниже. Прежде всего, на листовом уровне некластеризованного индекса, заданного на не-упорадоченной таблице, не находятся данные. Вместо этого листовой уровень применяется для получения указателя на искомые данные. Указатель представлен в форме идентификатора строки (RID), который, как уже было описано выше в настоящей главе, состоит из данных об экстенте, странице и смещении строки, относящихся к конкретной строке, на которую указывает индекс. Даже несмотря на то, что на листовом уровне отсутствуют действительные данные (вместо этого на этом уровне определены идентификаторы строк), для достижения искомых данных требуется пройти на один шаг больше по сравнению с той ситуацией, когда используется кластеризованный индекс; но поскольку в идентификаторе RID содержится полная информация о местонахождении строки, то обеспечивается возможность перейти непосредственно к данным. Но из того, что при использовании некластеризованного индекса, заданного на неупорадоченной таблице, приходится, как было сказано выше, осуществлять еще один шаг, не следует, что при его применении издержки увеличиваются лишь незначительно и что этот индекс обеспечивает почти такое же быстродействие, как кластеризованный индекс. Еще раз отметим, что данные, на которых определен кластеризованный индекс, имеют физическое расположение, соответствующее последовательности ключей в индексе. Это означает, что при выборке данных, относящихся к определенному диапазону, достаточно лишь найти строку, в которой начинаются требуемые данные, после чего со всей вероятностью остальные искомые строки будут обнаружены на той же странице (иными словами, для достижения следующей строки почти не требуется усилий, поскольку все нужные строки хранятся вместе). С другой стороны, при использовании неупорадоченной таблицы данные не являются связанными друг с другом каким-то иным способом, кроме как через индекс. Какая-либо физическая сортировка данных не осуществляется. Это означает, что для чтения данных из неупорядоченной таблицы в системе может возникнуть необходимость обращаться для выборки строк к любым участкам файла с данными. В действительности вполне возможно (и даже не подлежит сомнению), что в процессе работы для получения данных придется неоднократно считывать в разное время одну и ту же страницу, поскольку в СУБД SQL Server нельзя предугадать, что снова придется обращаться к какому-то участку файла, так как между данными отсутствует связь. С другой стороны, если применяется кластеризованный индекс, то система может определить, что данные хранятся в отсортированном порядке, и поэтому получить сразу все необходимые данные в результате чтения одной страницы.
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |