
|
|
Программирование >> Программирование баз данных
Корневой узел 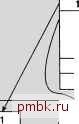 Нелистовой уровень 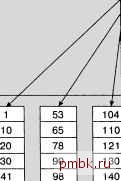  Листовой уровень Рис. 8.3. Организация поиска данных в многоуровневом индексе Более подробное описание процесса разбиения страницы Очевидно, что описанный процесс осуществляется столь бесперебойно, когда происходит чтение данных с помощью индекса, но операция обновления индекса является немного более сложной. Напомним, что буква В в слове В-дерево означает balanced (сбалансированный). Кроме того, как уже было сказано, В-дерево является сбалансированным, поскольку примерно половина данных находится по одну или по другую сторону от каждого узла дерева, из которого исходят ветви к узлам нижележащего уровня. Следует отметить, что В-деревья иногда называют самобалансирующимися, поскольку для вставки новых данных в дерево применяется такой метод, который обычно предотвращает появление асимметрии в дереве. По мере ввода в дерево новых данных происходит заполнение узлов, в результате чего в узлах в конечном итоге больше не остается свободного места и требуется их разбиение. Поскольку в СУБД SQL Server узел индекса представлен в виде страницы, то вместо указания на то, что происходит разбиение узла, принято применять термин разбиение страницы Процесс разбиения страницы показан на рис. 8.4. При каждом разбиении страницы автоматически происходит перемещение данных для обеспечения поддержки сбалансированности дерева. Первая половина данных остается на старой странице, а остальные данные переносятся на новую страницу. Таким образом, разбиение осуществляется примерно наполовину и дерево остается сбалансированным. Упорядоченная вставка в качестве средней записи в кластерный ключ
Должна быть вставлена новая запись, но страница уже заполнена Новая запись должна попасть в середину, поэтому необходимо выполнить разбиение страницы Рис. 8.4. Процесс разбиения страницы Даже краткие размышления по поводу того, как происходит процесс разбиения, позволяет понять, что во время разбиения возникают значительные издержки. Дело в том, что в процессе разбиения не происходит лишь вставка одной страницы, а выполняются следующие действия: создание новой страницы; перенос части строк с существующей страницы на новую страницу; добавление новой строки к одной из страниц; добавление еще одной строки в родительский узел. Но на этом работа не заканчивается. Поскольку узлы образуют древовидную структуру, создается предпосылка возникновения своего рода каскадных действий. После того как создается новая страница (в результате разбиения), возникает необходимость ввести еще одну строку в родительский узел. Появление новой строки в родительском узле также может привести к возникновению необходимости осуществить разбиение страницы, но уже на уровне родительских узлов, поэтому процесс разбиения возобновляется на более высоком уровне. В действительности такая последовательность операций может продолжаться, охватывая все более и более высокие уровни, и в конечном итоге может даже затронуть корневой узел. Если происходит разбиение корневого узла, то фактически в связи с этим создаются две дополнительные страницы. Но количество корневых узлов не может быть больше единицы, поэтому страница, на которой перед этим находились строки корневого узла, разбивается на две страницы, а уровень, на котором она находится. становится новым промежуточным уровнем дерева. После этого создается совершенно новый корневой узел, в котором содержатся две строки (одна из них относится к старому корневому узл)% а вторая - к странице, полученной в результате разбиения). Вполне очевидно, что выполняемые каскадно операции разбиения страниц могут оказывать весьма негативное влияние на производительность системы. Характерным признаком того, что происходит каскадное разбиение, является ситуация, в которой создается впечатление, что процессы обработки данных на сервере кажутся приостановившимися на несколько секунд (на то время, когда происходит разбиение и перезапись страниц). Информация о том, как предотвратить возникновение ситуаций разбиения страниц, приведена в конце данной главы. Безусловно, операции разбиения страниц на листовом уровне происходят очень часто, но такие операции в узлах промежуточных уровней происходят гораздо реже. По мере увеличения размеров таблицы операции разбиения страниц осуществляются на каждом уровне индекса, но в узлах промежуточных уровней имеется только по одной строке в расчете на несколько строк узла более нижого уровня, поэтому количество страниц, подвергаемых разбиению, становится все меньше и меньше по мере дальнейшего продвижения вверх по дереву. К тому же разбиение на уровне выше листового может иметь место лишь в том случае, если произогило разбиение на более низком уровне. Это означает, что операции разбиения страниц, осуществляемые на более высоких уровнях дерева, по своему характеру являются кумулятивными, т.е. возникающими в результате осуществления ряда подобных операций (и поэтому их выполнение связано с определенным снижением производительности). В СУБД SQL Server предусмотрен целый ряд различных типов индексов (информация об этом будет вскоре приведена), но в индексах всех этих типов в той или иной форме используется подход, основанный на применении В-деревьев. На самом деле все эти индексы весьма напоминают друг друга по своей структуре и вместе с тем обладают заметными отличительными особенностями, поскольку В-деревья позволяют реализовывать исключительно разнообразные требования. Однако, как будет описано ниже, некоторые различия между индексами разных типов действительно являются весьма существенными. Кроме того, от типа применяемого индекса во многом зависит производительность системы. Следует отметить, что в индексах SQL Server узлы дерева представлены в виде страниц, а сами индексы имеют древовидную структуру, которая включает корневой узел, узлы уровней, отличных от листового, и узлы листового уровня. Но подобный принцип организации данных может применяться не только в SQL Seruer, но и в других базах данных и даже в системах представления данных, отличных от баз данных. Принципы организации доступа к данным в СУБД SQL Server Вообще говоря, в СУБД SQL Server применяются только два указанных ниже способа выборки запрашиваемых данных. Выборка данных путем полного просмотра таблицы. Выборка данных с помощью индекса.
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |