
|
|
Программирование >> Программный интерфейс приложений
но если таблица содержит только несколько записей, удовлетворяющих критерию поиска. На рис. 4.2 показана эта же таблица, но уже проиндексированная по столбцу company num. Индекс содержит запись о каждой строке из таблицы, и записи индекса отсортированы по значению сотрапупшп. Теперь вместо простого просмотра всех записей таблицы мы можем воспользоваться индексом. Предположим, что требуется найти все строки, содержащие записи о компании с кодом 13. Сканирование возвращает 3 строки. Значения в индексе отсортированы, поэтому при достижении значения 14 можно смело завершать сканирование. После 14 мы уже не найдем искомых значений. При поиске значений, которые лежат где-то посередине, с помощью специальных позиционирующих алгоритмов можно перейти прямо к нужной строке без длительного линейного сканирования таблицы (например, методом бинарного поиска). Таким образом, можно быстро позиционироваться на первую совпадающую запись таблицы, сэкономив при этом массу времени. Базы данных используют различные методы быстрого позиционирования индексных значений и неважно, где эти методы находятся. Важно, что они работают, и то, что индексирование - отличный инструмент оптимизации. Можно спросить, почему бы просто не отсортировать данные и не назвать это индексным файлом? Не ускорит ли это процесс? Да, может быть, если у вас один индекс. Но если потребуется создать второй индекс, будет очень неудобно отсортировать одни и те же данные двумя различными способами одновременно. (Например, один индекс накладывается на имена потребителей, а второй - на идентификационные номера потребителей или на телефонные номера.) Рассмотрение индексов отдельно от файлов помогает решить проблему нескольких индексов. При добавлении или удалении новых значений намного проще просматривать более короткие индексные значения, чем продвигаться вдоль длинных строк с данными. Таблица ad
Рис. 4.1. Неиндексированная таблица Таблица ad 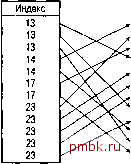
Рис, 4.2. Индексированная таблица Этот пример демонстрирует приемы индексирования таблиц СУБД MySQL. Данные таблицы хранятся в файле данных, а значения индексов хранятся в отдельном индексном файле. Одна таблица может иметь несколько индексов, которые хранятся в одном и том же индексном файле. Каждый индекс в индексном файле состоит из отсортированного массива ключевых записей, которые используются для быстрого доступа к файлу данных. Предьшущий пример демонстрирует преимущества индексов в контексте запроса к одной таблице, что резко уменьшает необходимость полного просмотра таблицы. Однако индексы еще более удобны при создании запросов, в которых задействовано несколько таблиц. В однотаб-личном запросе количество значений, анализируемых во время запроса, равно количеству строк в таблице. В запросах, затрагивающих несколько таблиц, количество комбинаций резко возрастает и равно произведению количества строк в таблицах. Предположим, у нас есть три неиндексированные таблицы tl, t2 и t3, содержащие столбцы с1, с2 и сЗ, соответственно, содержащие 1000 строк, пронумерованные от 1 до 1000. (Это достаточно простой пример, но на нем можно будет проиллюстрировать решение реальных проблем.) Запрос на выборку всех комбинаций табличных строк выглядит следующим образом: SELECT cl, с2, сЗ FROM tl, t2, t3 WHERE Cl = C2 AND cl = c3 Этот запрос возвратит 1000 строк, содержащих три равные значения. При обработке этого запроса при отсутствии индексов совершенно неизвестно, какое значение содержит какая строка. Необходимо перебрать последовательно все комбинации для того, чтобы найти те, которые удовлетворят условию в предложении WHERE. Количество вероятных комбинаций составляет 1000x1000x1000 (1 миллиард!), что в миллион раз больше числа совпадений. Это явно излишние усилия, и соверщенно справедливо можно ожидать, что этот запрос будет работать достаточно медленно, даже для такой быстрой базы данных как СУБД MySQL. И это только при таблице в 1000 строк. Что же будет, если таблицы будут иметь миллионы строк? Нетрудно заметить, что это быстро приведет к резкому ухудшению производительности. Индексирование этих таблиц сразу же приведет к ускорению обработки запросов, потому что при наличии индекса запрос обрабатывается следуюшим образом. 1. Делается выборка и просмотр содержимого первой строки таблицы tl. 2. Непосредственно в индексе таблицы t2 ишется строка в таблице, удовлетворяюшая условию выборки из таблицы tl. Аналогично, непосредственно в индексе таблицы t3 ишется строка в таблице, удовлетворяюшая условию выборки из таблицы tl. 3. Переходим к следующей строке в таблице tl и повторяем преды-душую процедуру. И так до тех пор, пока все строки таблицы tl не будут просмотрены. В этом случае по-прежнему осуществляется полный просмотр таблицы tl, но можно производить прямые просмотры таблиц t2 и t3. Запрос будет работать всего в миллион раз быстрее. Так СУБД MySQL использует индексы для ускорения поиска столбцов, удовлетворяющих условиям выборки из предложения where. Но это не единственное применение индексов. Они могут улучшить производительность и для следующих типов операций. Ускоряется поиск максимального или минимального значения индексируемого столбца при работе с функциями MIN () или МАХ (). Индексы можно использовать для ускорения сортировки с помошью конструкции order by. Иногда СУБД MySQL может избежать чтения из файла данных вообще. Предположим, производится выборка только значений индексированного столбца. В этом случае достаточно данных, полученных из индекса, чтения данных из файла данных не требуется. Недостатки индексирования В целом, можно научиться эффективно использовать индекс. Это значит, что в большинстве случаев, если вы не индексируете свои таблицы, вы вредите самому себе. Может показаться, что я рисую розовую картину, которая будет наблюдаться, если индексировать все таблицы во всех базах данных. А есть ли какие-нибудь изъяны в индексах? Да, есть. На практике они незначительны и многократно перекрываются Преимуществами от использования индексов. Но о них надо знать.
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |