
|
|
Программирование >> Хронологические базы данных
Глава Распределенные базы данных 20.1. Введение в конце главы 2 уже затрагивалась тема распределенных баз данных. При этом указывалось, что полная поддержка распределенных баз данных означает, что отдельное приложение может прозрачно обрабатывать данные, распределенные между множеством различных баз данных, управление которыми осуществляют разные СУБД, работающие на соединенных коммуникационными сетями мащинах разных типов с различными операционными системами. Здесь понятие прозрачно означает, что приложение выполняет обработку данных с логической точки зрения так, как будто управление данными полностью осуществляется одной СУБД, работающей на единственной мащине . В этой главе мы поговорим о распределенных базах данных подробнее, а именно - более точно определим, что такое распределенная база данных, почему такие базы данных играют все более важную роль и какие технические проблемы существуют в области распределенных баз данных. Кроме того, в главе 2 обсуждались системы клиент/сервер , которые можно рассматривать как простой частный случай распределенных систем вообще. Системы клиент/сервер будут рассмотрены в разделе 20.5. Общий план данной главы приведен в конце следующего раздела. 20.2. Предварительные сведения Начнем с рабочих определений, которые на этом этапе неизбежно будут не совсем точны. Система распределенных баз данных состоит из набора узлов (sites), связанных коммуникационной сетью, в которой: а) каждый узел - это полноценная СУБД сама по себе, но б) узлы взаимодействуют между собой таким образом, что пользователь любого из них может получить доступ к любым данным в сети так, как будто они находятся на его собственном узле. Из этого определения следует, что так называемая распределенная база данных в действительности является виртуальной базой данных, компоненты которой физически хранятся в нескольких реальных базах данных на нескольких различных узлах (в сущности, являясь логическим объединением этих реальных баз данных). Пример подобной структуры показан на рис. 20.1. Нью-Йорк Лондон /-N 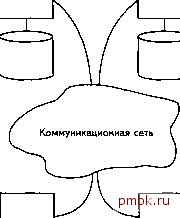 Лос-Анджелес Сан-Франциско Рис. 20.1. Пример типичной системы распределенной базы данных Еще раз отметим, что каждый узел сам по себе является системой базы данных. Иначе говоря, на каждом узле есть собственные локальные реальные базы данных, собственные локальные пользователи, собственные локальные СУБД и программное обеспечение управления транзакциями (включая собственные локальные системы блокировки, ведения журналов, восстановления и т.д.) и собственный локальный менеджер передачи данных. В частности, любой пользователь может выполнить операции над данными на своем локальном узле точно так же, как если бы этот узел вовсе не входил в распределенную систему (по крайней мере, так должно быть). Распределенную систему баз данных можно рассматривать как некоторое партнерство между отдельными локальными СУБД на отдельных локальных узлах. Новый программный компонент на каждом узле - логическое расширение локальной СУБД - предоставляет необходимые функциональные возможности для организации подобного партнерства. Именно этот компонент вместе с существующими СУБД составляет то, что обычно называется распределенной системой управления базами данных (РСУБД). Чаще всего предполагается, что узлы физически распределены (а возможно, и географически, как показано на рис. 20.1), хотя в действительности достаточно того, чтобы они были распределены логически. Два узла могут даже сосуществовать на одной и той же мащине (в особенности на начальном этапе тестирования). Главная цель создания распределенных систем со временем изменялась. В ранних исследованиях в основном предполагалась географическая распределенность, но в больщинстве первых коммерческих реализаций предполагалось локальное распределение, когда несколько узлов размещалось в одном здании и соединялось с помощью локальной сети (ЛВС). Однако позже стремительное распространение глобальных сетей (ГВС) снова пробудило интерес к возможности географического распределения. В любом случае это не имеет большого значения с точки зрения системы баз данных - решать, в основном, требуется одни и те же технические (связанные с базами данных) проблемы. Поэтому в настоящей главе мы можем обоснованно рассматривать представленную на рис 20.1 систему как типичного представителя распределенных систем. Замечание. Для упрощения изложения будем предполагать, если нет соответствующего явного указания, что система однородна. Однородна в том смысле, что на каждом узле работает некоторая копия одной и той же СУБД. Будем называть это предположением о строгой однородности. Возможности и особенности неоднородных систем будут проанализированы в разделе 20.6. Преимущества Зачем нужны распределенные базы данных? Основная причина заключается в том, что предприятия обычно уже распределены. Распределены по крайней мере логически, т.е. разделены на подразделения, отделы, рабочие группы и т.д. Очень часто они распределены и физически, т.е. разделены на заводы, фабрики, лаборатории и т.д. Из этого следует, что данные также обычно распределены, поскольку каждая организационная единица создает и обрабатывает собственные данные, относящиеся к деятельности этой единицы. Таким образом, информация предприятия разбивается на части, которые иногда называют островами информации. А распределенная система обеспечивает .мосты для их соединения в единое целое. Иначе говоря, распределенная система позволяет структуре базы данных отображать структуру предприятия - локальные данные могут храниться локально, в соответствии с логической принадлежностью, тогда как к удаленным данным доступ может осуществляться по мере необходимости. Для того чтобы лучше в этом разобраться, приведем пример. Рассмотрим еще раз рис. 20.1. Для простоты предположим, что есть только два узла, Лос-Анджелес и Сан-Франциско, и что наша система- это банковская система. Данные о счетах Лос-Анджелеса хранятся в Лос-Анджелесе, а данные о счетах Сан-Франциско- в Сан-Франциско. Преимущества подобной распределенной системы очевидны: эффективность обработки (данные хранятся в том месте, где доступ к ним требуется наиболее часто) плюс расширенные возможности доступа (при необходимости с помощью коммуникационной сети из Сан-Франциско можно получить доступ к счетам Лос-Анджелеса и наоборот). Пожалуй, наиболее важным преимуществом распределенных систем является, как уже было отмечено, отражение ими структуры предприятия. Конечно, существует множество других преимуществ, которые будут обсуждаться ниже в этой главе вместе с соответствующими аспектами. Однако следует отметить, что подобным системам свойствен и ряд недостатков, наиболее существенным из которых является повышенная слож-
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |