
|
|
Программирование >> Хронологические базы данных
Ql: RETRIEVE (S.SNAME) WHERE S.CITY = London AND S.Sl = SP.SI AND SP.QTY > 200 AND SP.PI = P.PI Еще раз применим аналогичный прием к запросу Q1, отделив от него запрос, в котором используется единственная переменная диапазона SP. Присвоим отделенному запросу имя D2, а оставшуюся после отделения часть запроса Q1 назовем Q2. D2: RETRIEVE INTO SP (SP.Sl, SP.PI) WHERE SP.QTY > 200 Q2: RETRIEVE (S.SNAME) WHERE S.CITY = London AND S.Sl = SP.SI AND SP.PI = P.PI Далее тем же методом отделим запрос с единственной переменной S. D3: RETRIEVE INTO S (S.Sl, S.SNAME) WHERE S.CITY = London Q3: RETRIEVE (S.SNAME) WHERE S.Sl = SP.SI AND SP.PI = P.PI И наконец отделим еще один запрос, в котором используются переменные SP и Р. D4: RETRIEVE INTO SP (SP.SI) WHERE SP.Pl = P.Pl Q4: RETRIEVE (S.SNAME) WHERE S.Sl = SP .Sl В результате исходный запрос QO оказался разбитым на три запроса с одной переменной, Dl, D2 и D3 (каждый из которых является проекцией выборки), и два запроса с двумя переменными, D4 и Q4 (каждый из которых является проекцией соединения). Сложившуюся в результате ситуацию можно схематично представить в виде структуры, показанной на рис. 17.3. 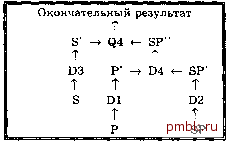 Рис. 17.3. Дерево деко.мпозиции запроса Q0 Эту схему можно интерпретировать следующим образом. в запросах D1, D2 и D3 в качестве входных данных используются переменные-отношения Р, SP и S (а точнее, те отношения, которые являются текущими значениями переменных-отношений Р, SP и S) соответственно, которые и помещают результат своего выполнения во временные переменные-отношения Р, SP и S соответственно. Далее выполняется запрос D4, использующий в качестве входных данных временные переменные-отношения Р и SP и помещающий результат своего выполнения во временную переменную-отношение SP. Наконец выполняется запрос Q4, использующий в качестве выходных данных переменные-отношения S и SP, результат выполнения которого и является результатом выполнения исходного запроса. Обратите внимание, что запросы D1, D2 и D3 полностью независимы и их можно обрабатывать в любом порядке (предположительно даже параллельно). Запросы D3 и D4 также можно обрабатывать в любом порядке, но только после получения результатов выполнения запросов D1 и D2. Запросы D4 и Q4 нельзя подвергнуть дальнейшей декомпозиции, поэтому их следует обрабатывать с помощью метода подстановки кортежей (что обычно обозначает применение поиска последовательным перебором (или метода грубой силы ), поиска по индексу или поиска в хешированном файле). В качестве примера рассмотрим выполнение запроса Q4. Обратившись к обычному набору данных, используемых в этой книге для примеров, можно определить, что множество номеров поставщиков в атрибуте SP . Sl будет выглядеть так: { S1, S2, S4}. Каждое из этих трех значений по очереди должно быть подставлено в атрибут SP .Sl. В результате запрос Q4 примет следующий вид. RETRIEVE (S.SNAME) WHERE S.Sl = Sl OR S.Sl = S2 OR S.Sl = S4 В [17.36] рассматриваются алгоритм разбиения исходного запроса на запросы с неприводимыми компонентами и алгоритм выбора переменных для подстановки кортежей. Именно от этого последнего из двух указанных алгоритмов во многом зависит общий успех оптимизации. Кроме того, в данной работе предложены эвристические подходы для оценки стоимости того или иного варианта (в системе INGRES обычно, но не всегда, для подстановки используется отношение с наименьшей кардинальностью). Основная задача процесса оптимизации - избежать выполнения декартовых произведений и минимизировать количество сканируемых кортежей на каждом этапе вычислений. В [17.36] не представлены алгоритмы оптимизации запросов с одной переменной. Однако информация об этом уровне оптимизации присутствует в общем обзоре системы INGRES [17.11]. Для оптимизации запросов с одной переменной в СУБД INGRES, в основном, используются функции, аналогичные подобным функциям в других системах. Они применяют хранящиеся в каталоге статистические данные, на основе которых выбирают конкретный путь доступа к требуемым данным (например, индекс или хеш-таблицу). В [17.37] представлены некоторые экспериментальные материалы (например, результаты измерения производительности для эталонного набора запросов), позволяющие сделать вывод, что описанные выше приемы оптимизации дают хорошие результаты и достаточно эффективны при применении на практике. Ниже приведены некоторые выводы, взятые из этой работы. 1. Метод отделения - это лучшая из методик, которую можно применять на первом этапе оптимизации. 2. Если на первом этапе нужно выполнять подстановку кортежей, то для этого лучше всего использовать переменную, по которой выполняется соединение. 3. Если к одной из переменных в запросе с двумя переменными применялась подстановка кортежей, то оптимальная тактика заключается в построении временного рабочего индекса или хеш-таблицы (если это еше не сделано) для того атрибута в другом отношении, по которому выполняется соединение. В СУБД INGRES эта тактика активно применяется. 17.7. Реализация реляционных операторов в этом разделе представлено краткое описание некоторых очевидных методов реализации отдельных реляционных операторов, в частности оператора соединения. Включение данного материала в книгу было вызвано стремлением развеять ту таинственность, которая все еще витает над описанием процесса оптимизации. Обсуждаемые далее методы соответствуют механизмам, которые в разделе 17.3 были названы низкоуровневыми процедурами реализации. Замечание. Более сложные приемы реализации описаны в аннотациях к определенным работам, ссылки на которые приведены в конце главы. Для простоты предположим, что кортежи и отношения физически хранятся на диске так, как они организованы логически. Далее будет рассмотрено выполнение операторов проекции, соединения и обобщения, причем под операторами обобщения будем понимать оба указанных ниже основных варианта. 1. Обобщение, результат которого не включает атрибутов. 2. Обобщение, результат которого включает как минимум один атрибут. Первый вариант достаточно прост. Как правило, в этом случае выполняется просмотр всего отношения, для которого вычисляется обобщающая функция, за исключением варианта, когда для обобщаемого атрибута имеется индекс. В последнем случае значение обобщающей функции может быть вычислено исключительно по значениям в файле индекса, без необходимости обращения к самому отношению [17.35]. Например, рассмотрим выполнение следующего запроса. SUMMARIZE SP ADD AVG ( QTY ) AS AQ Для вычисления его результатов достаточно просмотреть индекс по атрибуту QTY (предполагается, что такой индекс существует), вовсе не касаясь самой переменной-отношения поставок SP. Аналогичные соображения применимы и для функций COUNT и SUM (причем для функции COUNT подойдет любой индекс). Что касается функций МАХ и MIN, то их результат можно получить, выполнив единственную операцию чтения последней (для функции МАХ) или первой (для функции MIN) строки индекса (здесь вновь предполагается, что индекс для соответствующего атрибута уже существует). Далее в этом разделе будут рассматриваться обобщающие функции только второго типа (т.е. такие, результат вычисления которых включает значения хотя бы одного атрибута). Ниже показан пример операции обобщения второго типа. SUMMARIZE SP PER Р { Р# } ADD SUM ( QTY ) AS TOTQTY С точки зрения пользователя, операции проекции, соединения и операции обобщения второго типа, конечно, абсолютно не похожи одна на другую. Но с точки зрения реализации они имеют некоторое сходство, так как в каждом из случаев система должна сгруппи-
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |