
|
|
Программирование >> Хронологические базы данных
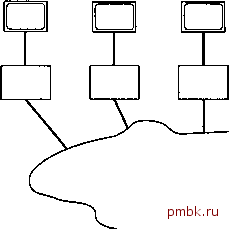 Машины клиентов Коммуникационная сеть
Рис. 2.7. Система с одним сервером и несколькими клиентами Отметим последнее преимущество, которое состоит в том, что отдельная машина клиента может иметь доступ к нескольким машинам серверов (случай, противоположный показанному на рис. 2.7). Это полезная возможность, поскольку, как уже упоминалось, предприятие обычно выполняет обработку данных таким образом, что полный набор всех данных сохраняется не на одной машине, а распределяется на нескольких различных машинах, причем в приложениях иногда необходим доступ к данным сразу нескольких машин. Такой доступ предоставляется, в основном, двумя способами. Клиент может получать доступ к любому количеству серверов, но лишь к одному из них в каждый момент времени (т.е. каждый запрос к базе данных может быть направлен только к одному серверу). В такой системе невозможно за один запрос получить комбинированные данные от двух или более серверов. Кроме того, пользователь в такой системе должен знать, на какой именно машине содержится конкретная часть данных. Клиент может получать доступ к любому количеству серверов одновременно (т.е. за один запрос можно получить комбинированные данные двух или более серверов). В этом случае серверы рассматриваются клиентом как единый сервер (с логической точки зрения) и пользователь может не знать, на какой именно машине содержится та или иная часть данных. Второй случай - это пример системы, которую обычно называют распределенной системой баз данных. Тема распределенных баз данных сама по себе весьма обширна. Подводя сказанное к некоторому логическому завершению, отметим еле- дующее: полная поддержка распределенных баз данных означает, что отдельное приложение может прозрачно обрабатывать данные, распределенные между множеством различных баз данных, управление которыми осуществляют разные СУБД, работающие на соединенных коммуникационными сетями машинах разных типов с различными операционными системами. Здесь понятие прозрачно означает, что приложение выполняет обработку данных с логической точки зрения так, как будто управление данными полностью осуществляется одной СУБД, работающей на единственной машине. Предоставление такой возможности может показаться невероятно трудной задачей, но весьма желанной с практической точки зрения. Производители СУБД напряженно работают, чтобы сделать подобные системы реальностью. Подробнее распределенные базы данных рассматриваются в главе 20. Клиенты Клиенты Сервер Клиенты Сервер Коммуникационная сеть 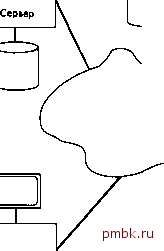 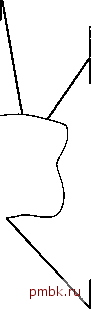 Клиенты Сервер Клиенты Сервер Рис. 2.8. Система, в которой каждая машина одновременно является и клиентом, и сервером 2.13. Резюме в этой главе системы баз данных рассматривались с точки зрения их общей архитектуры. Здесь была описана архитектура ANSI/SPARC, которая делит систему баз данных на три уровня следующим образом: внутренний уровень, наиболее близкий к физическому хранению (т.е. рассматривающий способ, с помощью которого данные сохраняются физически); внешний уровень, наиболее близкий к пользователям (т.е. имеющий отношение к способу представления данных для отдельных пользователей); концептуальный уровень, который является промежуточным между двумя предыдущими (он предоставляет обобщенное представление данных). Восприятие данных на каждом из уровней описывается с помощью схемы (или нескольких схем в случае внешнего уровня). Отображения описывают соответствие между заданной внешней схемой и концептуальной схемой, а также между концептуальной и внутренней схемами. Эти отображения служат основой для соответственно логической и физической независимости данных. Пользователи, т.е. конечные пользователи и прикладные программисты, работающие на внешнем уровне, взаимодействуют с данными с помощью подъязыка данных, который включает по крайней мере два компонента: язык определения данных и язык манипулирования данными. Подъязык данных встроен в базовый язык профаммирования. Замечание. Границы, разделяющие базовый язык и подъязык данных, а также язык определения данных и язык обработки данных по своей природе, в основном, умозрительны. В идеале, они должны быть прозрачны для пользователя. Здесь также детально рассматривались функции администратора базы данных и СУБД. Кроме всего прочего, АБД несет ответственность за создание внутренней схемы (физическое проектирование базы данных). В противоположность этому за создание концептуальной схемы (логическое или концептуальное проектирование базы данных) несет ответственность администратор данных. В функции СУБД входит также реализация запросов пользователей, написанных на языке определения данных или языке обработки данных. Функцией СУБД является и поддержка словаря данных. Системы баз данных удобно рассматривать как простую структуру, состоящую из сервера (собственно СУБД) и набора клиентов (приложений). Клиент и сервер могут выполняться и зачастую выполняются на отдельных машинах, обеспечивая таким образом простейший вариант распределенной обработки данных. В общем случае каждый сервер может обслуживать много клиентов, а каждый клиент может работать со многими серверами. Если система обеспечивает полную прозрачность доступа (т.е. клиент работает так, как будто он имеет дело с одним сервером на единственной машине, невзирая на реальное физическое положение дел), то в таком случае мы имеем настоящую распределенную систему баз данных. Упражнения 2.1. Начертите схему архитектуры системы баз данных, представленной в этой главе (архитектуры ANSI/SPARC). 2.2. Дайте определения следующим терминам. базовый язык отображение концептуальный- внутренний
|
||||||||||||
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |