
|
|
Программирование >> Полное сканирование таблицы
Например, если Custoi7ier ID - это свойство Orders, то это также наследованное свойство OrderDetails, соответствующих этим заказам. С денормализацией вы всегда можете протолкнуть свойства вверх по дереву соединения к узлам, находящимся над узлами, владеющими этими свойствами в нормализованном варианте. Такое наследование фильтрующих свойств не должно останавливаться на первом уровне. Например, Custonier Nanie, нормализованное свойство Customers, можно наследовать на два уровня вверх, через Orders, передав его в Order Details. Эта возможность проталкивать столбцы фильтрации вверх по дереву соединения на любую высоту подсказывает нам итоговое решение проблем производительности с распределенными фильтрами. Чтобы избежать проблем, вызванных распределенными фильтрами, продолжайте перемещать вверх самые селективные фильтрующие условия, пока они не соединятся в одном узле, который унаследует комбинированный фильтр, селективность которого равна произведению селектив-ностей исходных фильтров. В экстремальном случае все фильтры поднимаются на максимальную высоту в корневой детальный узел, и запрос считывает лишь несколько строк из этой таблицы, которые в итоге вернет, и соединяет их вниз с таким же количеством строк из находящихся ниже главных таблиц. В задаче, показанной на рис. 10.1, таблица М получает два денормализованных столбца, из В1 и В2 соответственно. Комбинированный фильтр для этих двух столбцов обладает селективностью 0,000001 (0,001 x 0,001), или одна строка из 1 ООО ООО, как показано на рис. 10.2. Оптимальный план выполнения для этой диаграммы запроса считывает 50 строк из М и выполняет вложенные циклы через индексы по первичным ключам, получая по 50 строк из всех остальных таблиц, А1, А2, В1 и В2. Это очень быстрый план. М 0.000001(=0.001х0.001) 5/\5 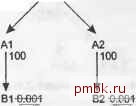 Рис. 10.2 Перемещение фильтров к верхним таблицам с использованием денормализации Возможно, вам покажется странным, что я упоминаю эту эффективную технику комбинирования фильтров так поздно в книге. Многие публикации предполагают, что денормализация является повсеместной необходимостью, но я с этим совершенно не согласен. В большинстве приложений, которые я настраивал, для настройки мне не потребовалось добавить ни одного элемента денормализации, а ведь именно настройка является единственной значимой причиной денормализации. Если вы будете следовать техникам, описанным в этой книге, то необходимость использовать денормализацию у вас также будет появляться крайне редко, только если вы столкнетесь со специфичным важным запросом, который другими способами ускорить невозможно. ПРИМЕЧАНИЕ Многие запросы можно ускорить при помощи денормализации, но не в этом дело. Дело в том, что даже без денормализации практически любой запрос можно сделать достаточно быстрым, применив правильную настройку. Улучшение в несколько миллисекунд не оправдывает стоимости денормализации. Большинство случаев, когда в целях улучшения производительности применяется денормализация, обеспечивают ненамного больше, чем крошечное улучшение, по сравнению с лучшей оптимизацией, возможной без денормализации. Если денормализация выполнена идеально, с тщательно проработанными триггерами базы данных, которые автоматически поддерживают точную синхронизацию денормализованных данных, то функционально она может быть безопасна. Однако ее нельзя назвать бесплатной - она требует дискового пространства и замедляет добавление, обновление и удаление данных, которые должны задействовать триггеры, отвечающие за синхронизацию данных. Столкнувщись с неизбежными затратами на денормализацию, я рекомендую применять ее только если вы встречаетесь со специфичным высокоприоритетным оператором SQL, который невозможно сделать достаточно быстрым другими способами. Но это действительно очень редкий случай. Приложение А. Решения задач в этом приложении содержатся решения для задач из глав с 5 по 7. Решения для задач из главы 5 Далее приведены решения для упражнений из главы 5. Упражнение 1 На рис. А.1 показано решение для упражнения 1. CCL4 20 12.5к Т1 41 d0j ROr Рис. А.1. Решение для упражнения 1 У решения этой задачи есть определенная тонкость. Тонкость этого упражнения заключается в том, что для поиска коэффициентов фильтрации узлов R и D запросы вообще не нужны (кроме общего количества строк для таблиц). Коэффициенты можно вычислить исходя из точного соответствия уникальных индексированных имен для каждого из этих узлов, однозначного соответствия для R и списка IN для D. Чтобы найти коэффициенты фильтрации, нужно только подсчитать 1/R и 2/D, где D и R это количество строк в соответствующих таблицах. Вы не забыли добавить звездочку (*) к коэффициенту фильтрации для R, чтобы указать, что это уникальное условие? Оказывается, это важно для оптимизации некоторых запросов. Можно было бы добавить звездочку для условия, налагаемого на таблицу D, если бы ему сопоставлялось одно имя вместо списка имен. Есть и еще одно допущение, позволяющее получить хороший план вьшолнения. Если предположить, что внешние ключи не равны null и ссылочная целост-
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |