
|
|
Программирование >> Полное сканирование таблицы
М - это корневая детальная таблица, вероятно, самая большая и хуже всех кэ-шированная во всем запросе. Пусть количество строк этой таблицы равно С. А1, А2 и A3 - это главные таблицы, которые присоединяются непосредственно к М. Все прочие таблицы - это также главные таблицы, и, вероятно, присоединяются к М не напрямую, а через промежуточные соединения. А10.3 А2 A3 В1 82 83 В4 0001 В5 07 С106 С2 05 СЗ С4 05 С5 02 Сб О? irif ...... D108 D2 Рис. 8.2. Чааично скрытая диаграмма запроса Даже имея такую скудную информацию, вы можете вычислить ключевое свойство стоимости считывания данных из самой большой и хуже всех кэшированной корневой детальной таблицы М. Количество строк, считанных из корневой детальной таблицы, будет не больше количества строк этой таблицы (С), умноженного на коэффициент фильтрации ведущей таблицы. Например, если фильтр, принадлежащий таблице В4,-это единственный фильтр, которым вы можете воспользоваться до соединения с М, то, начав с В4 и используя вложенные циклы, вы можете гарантировать, что считаете только одну тысячную строк М. Рисунок 8.3 иллюстрирует этот случай. Конечно, если В4 соединяется напрямую с другими узлами с фильтрами до того, как произойдет соединение с М, можно получить еще более хороший результат. Однако если вы выбираете соединения методом вложенных циклов, то сразу же можете утверждать, что верхняя граница стоимости считывания данных из корневой детальной таблицы равна С х Fd, где Fd - это коэффициент фильтрации выбранной ведущей таблицы. Это объясняет правило выбора ведущей таблицы, которое требует, чтобы ведущим был выбран узел с наименьшим коэффициентом фильтрации. Чтобы еще раз убедиться в справедливости правила, на рис. 8.4 связи, указанные на рис. 8.3, реорганизованы, чтобы новая диаграмма максимизировала преимущество варианта, альтернативного выбору ведущей таблицей таблицы 84. Теперь если вы начнете с А1 или любого узла под ней, то сможете использовать все фильтры кроме фильтра для В4 до того, как обработаете М. В результате из М будет считано количество строк, равное С х 0,0045 (С х 0,3 х 0,7 х 0,6 х 0,5 х 0,5 х 0,2 х 0,9 х 0,8), что более чем в четыре раза хуже, чем стоимость при выборе ведущей таблицей В4. Кроме того, с плохим первым фильтром стоимость доступа к другим таблицам в начале порядка соединения также будет высока, если только размер всех этих таблиц не окажется небольшим. 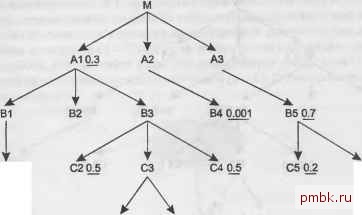 С10.6 С6 0.9 0108 D2 Рис. 8.3. Диаграмма запроса, на которой указаны возможные связи 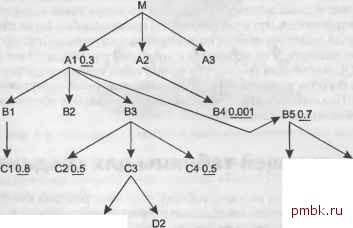 С5 0.2 С6 0.9 D10.8 Рис. 8.4. Диаграмма запроса, измененная, чтобы минимизировать недостатки выбора ведущей таблицей А1 Вы можете спросить, был ли этот пример предназначен для того, чтобы показать лучший ведущий фильтр в еще более привлекательном свете, но на самом деле это не так. В больпшнстве реальных запросов начать с наименьшего коэффициента фильтрации еще более выгодно! В запросах обычно намного меньше фильтров, которые можно скомбинировать, и эти фильтры сильнее распределены по различным ветвям под корневой детальной таблицей, чем в этом примере. Если у вас есть два одинаково хороших фильтра, то вы можете привести убедительные аргументы в пользу выбора ведущей таблицы с немного худшим фильтром, когда рядом с ней находится много узлов с также хорошими фильтрами, как, например, на рис. 8.5. 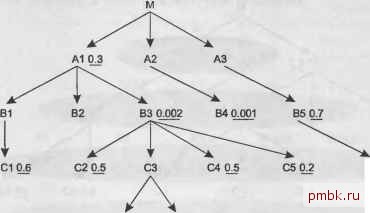 Сб 0.9 d1 08 d2 Рис. 8.5. Диаграмма запроса с конкурирующими ведущими узлами В этом сложном случае ВЗ, вероятно, была бы лучшим ведущим узлом, чем В4, так как ВЗ может воспользоваться помощью от соседних узлов перед тем, как вы проведете соединение с М. Это может выглядеть правдоподобно, и я не сомневаюсь, что такой случай может произойти, но, основываясь на своем опыте, могу сказать, что это все же редкость. Я не встречался с подобным случаем за 10 лет работы по настройке SQL, в основном потому, что чрезвычайно трудно встретить два очень селективных фильтра с практически одинаковой величиной селективности в одном запросе. Намного вероятнее, что селективность запроса обеспечивается одним очень селективным условием. Выбор следующей таблицы для соединения После того как вы выбрали ведущую таблицу, остальные решения в ходе создания надежного плана вьшолнения принадлежат к серии вопросов Что дальше? . Когда вы задаете этот вопрос, это означает, что у вас есть одно облако уже соединенных узлов, которые вы выбрали раньше в порядке соединения, и набор узлов, присоединенных к облаку, один из которых можно присоединить следующим. Если диаграмма запроса имеет обычную структуру дерева, максимум один узел будет находиться над текущим облаком, и любое количество узлов может свисать из него. На рис. 8.6 показан типичный случай. Рассмотрим вопрос Что дальше? в этой точке в порядке соединения. База данных получила некоторое количество строк, которое я обозначу KaKN. Соединения с таблицами ниже текущего облака соединения умножат текущее количество строк на какой-то коэффициент: коэффициент фильтрации, умноженный на глав-
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |