
|
|
Программирование >> Полное сканирование таблицы
ПРИМЕЧАНИЕ Как прочие правила в этой книге, эти правила вычисления корреляционного коэффициента подзапроса и уточненного коэффициента фильтрации подзапроса являются эвристическими. Так как точные числа редко необходимы для выбора правильного плана исполнения, эти тщательно спроектированные, надежные эвристические правила позволяют принять правильное решение по крайней мере в 90 % случаев, и практически никогда не выдают очень плохих решений. Как и во многих других частях книги, точное вычисление коэффициентов для сложного запроса находится далеко за пределами возможностей ручных методов настройки. Проверьте, как вы понимаете правила, вычислив корреляционный коэффициент предпочтения и уточненный коэффициент фильтрации для рис. 7.31, в котором не хватает этих двух чисел. 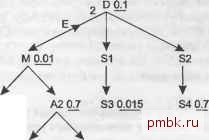 А10.2 BIOJ В2 Рис. 7.31. Сложный запрос, в котором отсутствуют нужные значения для полусоединения у вас несколько подзапросов), остановитесь. В этом случае коэффициент предпочтения подзапроса вам не понадобится, так как он нужен для принятия решения, только когда вы начинаете с внешнего запроса, но это не тот случай. 2. Если подзапрос - это однотабличный запрос без фильтрующего условия, только с условием корреляционного соединения, измерьте q (количество строк, возвращенное внешним запросом, если убрать условие подзапроса) и t (количество строк, возвращенное полным запросом, включая подзапрос). Уточненный коэффициент фильтрации подзапроса равен t/q. В этом сл5Д1ае условие EXISTS достаточно легко проверяется. База данных просто ищет первое совпадение в индексе соединения. 3. Иначе, для полусоединения, пусть D - это детальный коэффициент соединения. Пусть S - коэффициент фильтрации корреляционного узла (то есть узла, присоединенного к связи полусоединения) на детальном конце, то есть конце, принадлежащем подзапросу. 4. Если D <1, то уточненный коэффициент фильтрации подзапроса равен s х D. 5. Иначе, если s х D < 1, то уточненный коэффициент фильтрации подзапроса равен (D - 1 + (S X D))/D. 6. Иначе, пусть уточненный коэффициент фильтрации подзапроса равен 0,99. Даже очень плохо фильтрующее условие ЕХ ISTS позволит в действительности избежать увеличения количества строк и обеспечит лучшую стоимость фильтрации на единицу измерения, чем соединение вниз совсем без фильтра. Это последнее правило относится к случаям лучше, чем ничего (правда, ненамного лучше). Проверьте свой ответ, прочитав следующее объяснение. Вычислим корреляционный коэффициент предпочтения. 1. Пусть D = 2 и М = 1 (что подразумевает отсутствие этого числа на диаграмме). Пусть S = 0,015 (наилучший коэффициент фильтрации среди всех в подзапросе, принадлежащий таблице S3, которая находится на два уровня ниже корневой детальной таблицы D подзапроса). Пусть теперь R = 0,01, то есть равно значению наил5Д1шего фильтра среди всех узлов дерева под корневой детальной таблицей М внешнего запроса, включая этот узел. 2. Найдем D х S = 0,03 и М х R = 0,01; следовательно, D х S > М х R. Перейдем к шагу 3. 3. Так как S > R, то корреляционный коэффициент предпочтения равен S/R, то есть 1,5. Чтобы найти уточненный коэффициент фильтрации подзапроса, сделайте следующее. 1. Обратите внимание, что корреляционный коэффициент предпочтения больше 1, поэтому необходимо перейти к шагу 2. 2. Обратите внимание, что подзапрос включает несколько таблиц и содержит фильтры, поэтому необходимо перейти к шагу 3. 3. Найдем D = 2, и найдем коэффициент фильтрации для узла D, s = 0,1. 4. Так как D > 1, необходимо перейти к шагу 5. 5. Вычислим S X D = 0,2, что меньше 1, поэтому уточненный коэффициент фильтрации вычисляется как (D - 1 -I- (s х D))/D = (2 - 1 -i- (0,1 х 2))/2 = 0,6. В следующем разделе, посвященном оптимизации подзапросов EXISTS, я проиллюстрирую оптимизацию полной диаграммы, показанной на рис. 7.32. Диаграммное изображение подзапросов NOT EXISTS Условия подзапроса, которые можно выразить при помощи NOT EXISTS или NOT IN, проще, чем подзапросы типа EXISTS, в одном отношении - невозможно перейти от подзапроса наружу к внешнему запросу. Это устраняет необходимость в корреляционном коэффициенте предпочтения. Буква Е, указывающая условие подзапроса типа EXISTS, заменяется на букву N, чтобы обозначить условие подзапроса типа NOT EXISTS, а корреляционное соединение теперь называется антисоединением, а не полусоединением, так как оно предназначено для поиска сл5Д1ая, когда для соединения со строками из подзапроса не находится соответствия. Оказывается, практически всегда условия подзапроса типа NOT EXISTS Л5Д1ше выражать при помощи NOT EXISTS, а не при помощи NOT IN. Рассмотрим следующий шаблон для подзапроса NOT IN: SELECT .. FROM ... Outer Anti Joined Table Outer WHERE... AND Outer.Sonie Key NDT IN (SELECT Inner.Somejey FROM ... Subquery Anti Joined Table Inner WHERE <Условия и соединения для таблиц подзапроса>) Можно и нужно перефразировать этот шаблон в эквивалентную форму NOT EXISTS: ч SELECT ... FROM ... Outer Ant1 Joined Tab1e Outer WHERE andOuter.Sonie Key IS NOT NULL AND NOT EXISTS (SELECT null FROM ... Subquery Anti Joined Tab1e Inner WHERE <Условия и соединения для таблиц подзапроса> and Outer.Sonie Key - Inner.Sonie Key) ПРИМЕЧАНИЕ Чтобы преобразовать NOT IN в NOT EXISTS без изменения функциональности, необходимо добавить условие NOT nul 1 для ключа корреляционного соединения во внешней таблице. Причиной служит то, что условие NOT IN эквивалентно набору условий не равно , соединенных условием ИЛИ, но база данных не считает выражение NULL ! - <Некоторое значение> истинным, поэтому форма NOT IN отбрасывает все строки из внешнего запроса с равными null ключами корреляционного соединения. Этот факт малоизвестен, поэтому, вероятно, действительным намерением разработчика такого запроса является включение в результат запроса строк, которые форма NOT IN незаметно исключает. При преобразовании форм у вас появляется отличная возможность найти и исправить эту вероятную ошибку. Условия подзапросов типа EXISTS и NOT EXISTS прекращают поиск соответствий сразу же после того, как находят первое соответствие, если таковое существует. Условия подзапроса NOT EXISTS потенциально полезнее, если применять их рано в плане исполнения, так как, когда они быстро останавливаются с найденным соответствием, то отбрасывают соответствующую строку, а не сохраняют ее, что делает следующие шаги плана быстрее. Напротив, чтобы отбросить строку с условием EXISTS, база данных должна проверить все потенциально подходящие строки и исключить их - это более дорогая операция, если в полусоединении для каждой главной строки существует много детальных записей. Помните следующие правила для сравнения условий EXISTS и NOT EXISTS, указывающих на детальные таблицы от главной таблицы во внешнем запросе: Проверка неселективного условия EXISTS недорога (так как соответствие находится просто, обычно в первой же проверенной строке полусоединения), но отбрасывает немного строк из внешнего запроса. Чем больше строк вернет подзапрос, тем дешевле и менее селективна проверка условия EXISTS. Если же условие EXISTS селективно, то его проверка, вероятнее всего, дороже, так как при этом должно исключаться соответствие для каждой детальной строки. Проверка селективного условия NOT EXISTS недорога (так как соответствие находится просто, обычно в первой же проверенной строке полусоединения) и отбрасывает много строк из внешнего запроса. Чем больше строк вернет подзапрос, тем дешевле и селективнее проверка условия NOT EXISTS. С другой стороны, проверка неселективных условий NOT EXISTS также дорога, так как для каждой детальной строки необходимо подтверждение, что соответствия не существует. Так как преобразование условий подзапроса NOT EXISTS в эквивалентные простые запросы без подзапросов и дорого, и не слишком полезно, л}Д1ше использовать подзапросы NOT EXISTS на обоих концах антисоединения: там, где находится главная таблица, и там, где детальная. Очень редко возникает необходимость поиска альтернативных способов выражения условия NOT EXISTS.
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |