
|
|
Программирование >> Полное сканирование таблицы
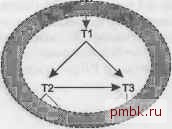 Рис. 7.3. Циклическое соединение, подразумевающее денормализацию В этом операторе SQL я назвал внешние ключи, указывающие из Т1 на 12 и ТЗ, FKeyl и FKey2 соответственно. По закону транзитивности значение столбца внешнего ключа Т2. FKey2 равно значению Т1. FKey, так как оба ключа соединяются с ТЗ. РКеуЗ. Первичные ключи Т2 и ТЗ называются РКеу2 и РКеуЗ, соответственно. Самое вероятное объяснение того, что Т1 и Т2 соединяются с одной таблицей, ТЗ, по ее полному первичному ключу заключается в том, что Т1 и Т2 содержат избыточные внещние ключи, указывающие на эту таблицу. В этом сценарии в столбце FKey2 детальной таблицы Т1 содержатся денормализованные данные из ее главной таблицы Т2. Эти данные всегда равны значению FKey2 в соответствующей главной строке таблицы Т2. ПРИМЕЧАНИЕ Предполагается, что значения FKey2 совпадают, но обычно это не так, потому что денормализованные данные чаще всего не синхронизированы. В главе 10 перечислены аргументы за и против денормализации в подобных случаях. Вкратце, если денормализация оправдывает себя, возможно, что дополнительная связь на диаграмме запроса предоставит вам доступ к лучшему плану исполнения. Однако более вероятно, что денормализация - это ошибка, стоимость и риск которой превосходят преимущества. Отказ от денормализации означает удаление внешнего ключа FKey2 в Т1, таким образом устраняя связь от Т1 к ТЗ и превращая диаграмму запроса в дерево. Случай 3. Двухузловой фильтр (не уникальный на обоих концах) уже связан при помощи обычных соединений На рис. 7.4 показан третий основной случай циклических соединений. На этот раз у нас есть обычные указывающие вниз стрелки от Т1 к Т2 и ТЗ, но также присутствует третье, необычное условие соединения между Т2 и ТЗ, которое не задействует первичного 101юча ни одной из двух таблиц. ПРИМЕЧАНИЕ Так как ни один из первичных ключей не используется в соединении между Т2 и ТЗ, у связи между ними нет стрелки ни на одном конце. SQL-код для рис. 7.4 выглядит следующим образом: SELECT ... FROM ...Tl. ... Т2. ... ТЗ.... WHERE ... Tl.FKeyl - Т2.РКеу2 AND Tl.FKey2 - ТЗ.РКеуЗ AND Т2.Со12<Каким-то образом сравнивается с>ТЗ.Со13 ... 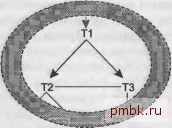 Рис. 7.4. Циклическое соединение с двухузловым фильтром Например, если Т1-это псевдоним таблицы Orders, которая соединяется с Customers, Т2, и Sal espersons, ТЗ, то это может означать, что запросу требуются заказы, покупате ли и ответственные продавцы в которых связаны с разными регионами: SELECT ... FROM Orders Tl. Customers T2. Salespersons T3 WHERE Tl.Customer ID = T2.Customer ID AND Tl.Salesperson ID = T3.Salesperson ID AND T2.Region ID! = T3.Region ID Здесь условие Т2. Regi on ID! = ТЗ. Regi on ID - это, строго говоря, соединение, но лучше рассматривать его как условие фильтрации, которому строки из двух различных таблиц требуются еще до того, как его можно применить. Если вы проигнорируете эту необычную связь между Т2 и ТЗ, то обращение к Т1 будет проходить до применения двухузлового фильтра по Region ID. Единственные порядки соединения, которые избегают непосредственного вьтолнения необычного соединения между Т2 и ТЗ, это: (Т1. Т2. ТЗ) (Т1. ТЗ. Т2) (Т2. Т1. ТЗ) (ТЗ. Т1. Т2) Любой другой порядок (например, (Т2. ТЗ. Т1)), после обработки второй таблицы создал бы ужасающее сочетание строк вида многие ко многим , практически декартово произведение строк из Т2 и ТЗ. Все перечисленные ранее порядки соединения обрабатывают Т1 первой или второй, перед тем, как обработать обе таблицы Т2 и ТЗ. Таким образом, эти порядки соединения выполняют только два обычных соединения многие к одному между детальной таблицей Т1 и ее главными таблицами Т2 и ТЗ. Необычный двухузловой фильтр не ведет себя как обычный фильтр, когда вы достигаете первой из двух фильтрованных таблиц. Но потом, когда вы обрабатываете вторую таблицу, работает как обычный фильтр, отбрасывая некоторую часть строк. С этой точки зрения обработка такого случая проста: считать, что фильтр не существует (или недостижим напрямую), пока не будет произведено соединение с одной из фильтрованных таблиц. Однако как только с любым из концов двухузлового фильтра будет выполнено соединение, противоположный узел неожиданно получит лучший коэффициент фильтрации и станет лучшим выбором для следующего присоединения. На рис. 7.5 показан специфический пример с двухузловым фильтром, в котором доля строк из обычных соединений от Т1 к Т2 и ТЗ, удовлетворяющих условию дополнительного двухузлового фильтра, равна 0,2. В этом случае сначала выбирайте порядок соединения независимо от существования этого фильтра, следуя только по обычным связям. Однако как только произойдет соединение с Т2 или ТЗ, коэффициент фильтрации противоположной таблицы (0,1 для Т2 и 0,5 для ТЗ) станет равен исходному, умноженному на 0,2, превращаясь в привлекательный выбор для будущих соединений. Т1 0.01 ▼ Т2-0.2-ТЗ 0.5 Т4 0.3 Т5 0 Рис. 7.5. Двухузловой фильтр с явным двухузловым коэффициентом фильтрации Следуйте обычной процедуре, чтобы настроить диаграмму на рис. 7.5, игнорируя двухузловой фильтр между Т2 и ТЗ, пока не достигнете одной из этих таблиц. Ведущая таблица - Т1, за ней Т4 - таблица под Т1 с наилучшим обычным фильтром. Далее у ТЗ лучший обычный фильтр с коэффициентом фильтрации 0,5, поэтому она помещается в порядок соединения следующей. Теперь необходимо выбрать между Т2 и Т5, но для Т2 активирован двухузловой фильтр, поскольку ТЗ уже обработана, что дает ей более эффективный коэффициент фильтрации (0,2), чем у Т5, поэтому присоединяем Т2 следующей. Итоговый лучший порядок соединения (Т1. Т4. ТЗ. Т2. Т5). ПРИМЕЧАНИЕ Соединение с Т2 в предьщущем примере - это обычное соединение, которое выполняется методом вложенных циклов от внешнего ключа, указывающего вниз из Т1, к индексу по первичному ключу Т2. Избегайте вложенных циклов для таблицы, с которой связан двухузловой фильтр. Возвращаясь обратно к SQL-коду перед рис. 7.5, можно заметить, что гораздо выгоднее обратеться к таблице Customers методом вложенных циклов, выполняя соединение Tl.Customer ID = T2.Customer ID, чем условия двухузлового фильтраT2.Region ID! = T3.Region ID. Случай 4. Составное соединение от двух внешних ключей к составному первичному ключу разложено на две таблицы Наконец, на рис. 7.6 представлен четвертый из основных случаев циклических соединений. Здесь присутствуют два необычных соединения с ТЗ, и ни в одном из них не используются ни полный первичный 1а1юч этой таблицы, ни первичные 1СЛЮЧИ таблиц на противоположных концах соединений. Если такие случаи, когда не удается произвести соединение с полным первичным 1слючом хотя бы на одной стороне соединения, это ошибки, то случай 4 - это случай, когда две ошибки компенсируют друг друга.
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |