
|
|
Программирование >> Полное сканирование таблицы
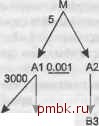 8103 82 05 Рис. 6.32. Иллюстрация запроса, требующего соединений хэшированием С другой стороны, когда вы выполняете соединение вниз по направлению к главной таблице, то это может быть соединение с намного меньшей таблицей, и стоимость получения строк через первичный ключ может быть больше, чем стоимость независимого считывания таблицы для соединения хэшированием. Из статистики на рис. 6.32 можно узнать, что в А1 в 3000 раз больше строк, чем в В1. Даже отбросив 999 строк из 1000 из А1, база данных выполнит соединение с каждой строкой из 81 в среднем три раза. Предположим, что в А1 3 ООО ООО строк, а в 81 1000 строк. После уменьшения А1 до 3000 строк с использованием ведущего фильтра база данных выполнит соединения со строками таблицы 81 3 ООО раз. Если база данных будет считывать 81 через ее собственный фильтр, ей понадобится считать лишь 300 (0,3 х 1000) строк, по приблизительно 1/10 стоимости. Так как запрос получает более 20 % строк из 81, база данных обнаружит даже меньшую стоимость, просто выполнив полное сканирование таблицы 81 и отфильтровав результат перед выполнением соединения хэшированием. Таким образом, не изменяя оставшуюся часть стоимости, выбор соединения хэшированием с 81 практически полностью устранит стоимость считывания из таблицы 81 по сравнению со стандартным надежным планом, который считывает 81 через вложенные циклы. Когда вы встречаете большие детальные коэффициенты соединения, соединения хэшированием с главными таблицами могут оказаться быстрее. Но насколько велико улучшение? В этом примере частичное улучшение для одной таблицы было достаточно большим, более 90 %, но абсолютное улучшение не столь значительно, приблизительно 9000 операций логического ввода-вывода (6000 в двухуровневом ключевом индексе и 3000 в таблице), что займет приблизительно 150 миллисекунд. Вы не найдете никаких операций физического ввода вывода для таблицы и индекса такого размера. С другой стороны, этот запрос считает приблизительно 2 250 строк (3000 х 0,3 х 0,5 х 5) из 15 ООО ООО-строчной таблицы М, выполнив 3600 операций логического ввода-вывода. ПРИМЕЧАНИЕ Вложенные циклы выполняют 450 (3000 х 0,3 х 0,5) сканирований диапазонов для индекса по внешнему ключу, указывающему на М, и для этого требуется 350 (450 х 3) операций логического ввода-вывода в трехуровневом индексе. Затем последуют 2250 операций логического ввода-вывода для таблицы, чтобы считать 2250 строк из М. Так, общее количество операций логического ввода-вывода будет равно 3600 (1350 + 2250). Эти 3600 операций логического ввода-вывода, особенно 2250 для искомой таблицы, потребуют сотен операций физического ввода-вывода для такой большой, трудно кэшируемой таблицы. Если на одну операцию физического ввода-вывода потребуется 5-10 миллисекунд, то считывание из М займет секунды. Это пример типичного случая, когда соединения хэшированием выполняются лучше. В таких случаях улучшение обеспечивается обычно только в операциях логического ввода-вывода для самых маленьких таблиц, и это улучшение очень невелико по сравнению со стоимостью оставшейся части запроса. Две эмпирические формулы помогут вам выбрать лучший метод соединения: H-CxR L=CxDxFxN Переменные в этих формулах определяются следующим образом. Н - количество операций логического ввода-вывода, необходимых для независимого считывания главной таблицы при выполнении соединения хэшированием. С - количество строк, возвращенных из главной таблицы. R - коэффициент фильтрации главной таблицы. Предполагайте, что база данных считывает таблицу независимо, при помощи сканирования диапазона индекса по этому фильтру. L - количество операций логического ввода-вывода, необходимых для считывания из главной таблицы при помощи вложенных циклов по ее первичному ключу. D - детальный коэффициент соединения для связи, которая ведет вверх от главной таблицы, и обычно указывает, насколько эта таблица меньше детальной таблицы наверху, ш F - произведение всех коэффициентов фильтрации, включая ведущий коэффициент, обработанный до этих соединений. N - количество операций логического ввода-вывода, необходимых для считывания одной строки через индекс по первичному ключу. Так как первичные ключи до 300 строк обычно помещаются в корневой блок, то N = 2 (1 для корневого блока индекса и 1 для таблицы), если С меньше 300. N - 3, если С находится между 300 и 90 ООО. N - 4, если С между 90 ООО и 27 ООО ООО. Так как обычно вы будете начинать с наилучшего коэффициента фильтрации, то F < R, даже если план не обнаружит дополнительных фильтров после фильтра для ведущей таблицы. Н меньше L, что говорит в пользу соединения хэшированием для стоимости логического ввода-вывода, когда R<CxFxN. F<R, когда вы начинаете с узла с наилучшим коэффициентом фильтрации. N невелико, как показано, так как В-деревья на каждом уровне сильно разветвляются. Таким образом, чтобы выбрать соединение хэшированием, либо F по абсолютному значению должно быть близко к R, либо D велико, превращая это соединение в соединение с намного меньшей по размеру главной таблицей. Те же вычисления иногда будут демонстрировать эконо- ПРИМЕЧАНИЕ Если вы начали не с наилучшего порядка соединения, замена соединений с вложенными циклами соединениями хэшированием может привести к большой экономии, потому что в этом случае первые таблицы не гарантируют использования для них лучших фильтров (то есть они не гарантируют, что F < R). Плохо оптимизированные порядки соединения могут выполнять поиск в соединении слишком много раз. Если вы обнаружите, что запрос демонстрирует огромное улучшение с соединением хэшированием, следует заподозрить, что для него выбран очень плохой порядок соединения, или же он не обращается к присоединяемой таблице через индекс по полному ключу соединения. Затем замените вложенные циклы для главной таблицы оптимизированным однотабличным путем доступа и соединением хэшированием в этой же точке порядка соединения. Это изменение не повлияет на стоимость обращения к другим таблицам, но отделит этот вариант от других возможных вариантов оп- мию логического ввода-вывода при соединении с большой главной таблицей, но будьте осторожны. Если главная таблица слишком велика, чтобы хорошо кэширо-ваться, в игру вступает физический ввод-вывод, что приводит к стремлению запретить соединение хэшированием по двум причинам. Так как строки таблиц намного хуже кэшированы, чем блоки индекса, преимущество стоимости соединения хэшированием (если оно присутствует), когда стоимость физического ввода-вывода сильно доминирует, сравнимо с количеством строк таблицы, что ставит вопрос, верно ли, что R < D х F. Поскольку ввод-вывод для индекса намного лучше кэширован, чем ввод-вывод для таблицы, стоимость, определяемая физическим вводом-выводом, для считывания индексных блоков уменьшается в N раз. Без множителя N соединения хэшированием выглядят не настолько привлекательно. Если С x R велико, при соединении хэшированием может понадобиться записать предварительно хэшированные строки на диск и затем снова считать, что делает соединение хэшированием намного дороже и потенциально может привести к ошибкам недостатка дискового пространства во время вьшолнения запроса. Это риск надежности упомянутых вложенных циклов. В целом, сложно найти реальные запросы, для которых экономия, полученная на соединениях хэшированием, по сравнению с наилучшим надежным планом будет оправдывать приложенные усилия. Праетически единичные случаи большой экономии на соединениях хэшированием возникают, когда запрос начинается с плохого ведущего фильтра и обращается к большим таблицам, что неизбежно означает, что весь запрос вернет неразумно большой набор строк. Однако это не подразумевает, что соединения хэшированием - ошибка. Стоимостные оптимизаторы ищут небольшие улучшения с таким же усердием, как и действительно существенные, и они успешно справляются с поиском случаев, в которых соединения хэшированием немного помогают. Хотя я практически никогда не ухожу с обычного пути, чтобы насильно в101ючить соединение хэшированием, но я и не пытаюсь исправить выбор оптимизатора, если он выбирает такое соединение для небольшой таблицы (а он часто так делает), не портя при этом порядок соединения и выбор индексов. Если вы сомневаетесь, то всегда можете поставить эксперимент. Но сначала найдите наилучший надежный план с вложенными циклами.
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |