
|
|
Программирование >> Полное сканирование таблицы
ловину отделов. Результат показан на рис. 6.19, где каждый узел обозначен первой буквой имени соответствующей таблицы. 0.01 Рис. 6.19. Простой пример с фильтрующим соединением ПРИМЕЧАНИЕ Обратите внимание, что на рис. 6.19 для L указан коэффициент фильтрации 1,0, что означает, что для L нет фильтра. Обычно такие коэффициенты не указываются. Однако я включил в диаграмму коэффициент фильтрации для L, чтобы объяснить, что число 0,01 в верхней части связи с L - это детальный коэффициент соединения для связи от Е к L, а не коэффициент фильтрации для L. Предположим, что у нас есть 1000 сотрудников, 10 отделов и 10 займов для 8 из этих сотрудников. Пусть единственный фильтр отбрасывает половину отделов. Детальный коэффициент фильтрации для Loans должен быть равен 0,01, так как после соединения 1000 сотрудников с таблицей Loans мы найдем только 10 займов. Исходные правила требуют, чтобы мы начали с единственной фильтрованной таблицы. Departments, считали 5 строк, соединили с половиной сотрудников (еще 500 строк), и затем соединили с приблизительно половиной займов (для приблизительно 4 сотрудников в выбранной половине отделов). Таким образом, база данных считает 5 займов, выполнив 496 безуспещных операций сканирования диапазонов индекса Employee ID для Loans, используя идентификаторы Employee ID сотрудников без займов. С другой стороны, если таблица Loans унаследует преимущество фильтрующего соединения, то вы бы начали с Loans, считали из нее все 10 строк, а затем нашли бы 10 соответствующих строк в Employees (8 различных строк с повторениями). Наконец, 10 раз выполнили бы соединение с Departments, причем база данных отбросила бы в среднем половину строк. Хотя обычная цель оптимизации - минимизировать количество строк, считанных из основной таблицы, этот пример демонстрирует, что минимизация количества операций считывания из таблицы на верхнем конце сильно фильтрующего детального соединения гораздо менее важна, чем минимизация количества строк из намного большей таблицы на нижнем конце. Насколько хорошим должен быть фильтр для Empl oyees, чтобы снизить количество строк, считанных из этой таблицы, до количества строк во втором плане? Фильтр должен быть в точности таким, как коэффициент фильтрующего соединения, 0,01. Предположим, что он даже лучше - 0,005, и пропускает только 5 сотрудников (скажем, это фильтр по Last Name). В этом случае какую таблицу следует присоединить следующей? Опять-та1Ш исходные правила привели бы нас к Departments, потому что она находится ниже и потому что у нее лучше коэффициент фильтрации. Однако обратите внимание, что для 5 сотрудников база данных считает в среднем только 0,05 займов, поэтому гораздо лучше сначала соединить с таблицей Loans, а затем с Departments. ПРИМЕЧАНИЕ в действительности конечный пользователь, скорее всего, выберет фамилию одного из сотрудников, получившего заем, сделав эти фильтры более зависимыми, чем обычно. Но даже в этом случае займов будет всего один или два, что сократит соединение с Departments до считывания всего одной или двух строк вместо пяти. Оптимизация детальных коэффициентов соединения, меньших 1,0, по формальным правилам На рис. 6.20 показан еще один пример с детальным коэффициентом соединения, меньшим 1,0. Перед тем как продолжать чтение, попробуйте найти порядок соединения самостоятельно.  А10.01 А2 В10.8 В20.05 Рис. 6.20. Пример с детальным коэффициентом соединения, меньшим 1,0 Сначала изучим влияние коэффициента соединения на выбор ведущей таблицы. На рис. 6.21 я показал корректировки коэффициентов фильтрации с точки зрения правильного выбора ведущей таблицы. После того как эти изменения будут внесены, эффективный фильтр для М, равный 0,003, станет лучшим, поэтому начинаем цепочку соединений с таблицы М. На этой точке нужно вернуть исходные коэффициенты фильтрации, чтобы выбрать дальнейший порядок соединения, так как, если начать с любого узла (М, А2 или В2) на детальной стороне соединения, коэффициент соединения не будет более играть роли. В более сложном запросе может показаться, что подсчитать все эти эффективные значения фильтров для множества узлов на одной стороне фильтрующего соединения очень сложно. На практике необходимо просто найти наилучшие коэффициенты фильтрации на каждой стороне (0,01 для А1 и 0,03 для М в данном случае) и сделать единственную корректировку для наилучшего коэффициента фильтрации на стороне соединения с фильтром. ПРИМЕЧАНИЕ Если у коэффициента соединения сохраняется постоянный эффект на протяжении всей оптимизации запроса, вы просто можете внести этот эффект в коэффициенты фильтрации. Но если эффект изменяется во время процесса оптимизации, лучше записывать эти числа отдельно. При выборе дальнейшего порядка соединения сравните исходные коэффициенты фильтрации для А1 и А2 и выберите А1. Сравнив В1 и А2, выберите В1. Порядок соединения на данный момент - (М. А1. В1). Оставшаяся часть порядка соединения полностью ограничена скелетом соединения, и полный порядок выглядит как (М. А1. В1. А2. В2). М JxR=0.1x0.03=0.003 А10.01 A2JxR=0.1x1=0.1 Bl 0 8 82 JxR=01x0=0.005 Рис. 6.21. Эффективные фильтры для выбора ведущей таблицы Рисунок 6.22 приводит к точно такому же результату. Не имеет значения, что в этот раз наименьший начальный коэффициент фильтрации не связан напрямую с фильтрующим соединением. Все узлы на фильтрованной стороне соединения получают преимущество фильтра соединения при выборе ведущей таблицы, а все фильтры на другой стороне соединения - нет. Ни у А1, ни у А2 нет фильтров, идущих от М, поэтому выберите первым узел А1, так как фильтр следующего шага для В1 лучше. Порядок соединения будет таким же, как в предыдущем примере. MODS 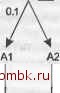 В1001 В2 О05 Рис. 6.22. Еще один пример с детальным коэффициентом соединения, меньшим 1,0 На рис. 6.23 узлы М и В2 получают одинаковое преимущество от фильтрующего соединения, поэтому просто сравните исходные коэффициенты фильтрации и выберите В2. Начиная с этой точки, порядок соединения будет полностью ограничен скелетом соединения - (В2. А2. М. А1. В1). На рис. 6.24 снова сравниваются только фильтрованные узлы на одной стороне фильтрующего соединения, но заметили ли вы влияние на последующий порядок соединения? Преимущество фильтрующего соединения появляется, только если вы выполните соединение в этом направлении. Так как вы начинаете с А2, соединение этого узла с М проводится обычным соединением вида один ко многим , которое следует отложить на как можно более поздний срок. Тагсим образом, следует выполнить
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |