
|
|
Программирование >> Полное сканирование таблицы
рядок соединения, не обращая внимания на коэффициент фильтрации, который мог бы быть указан. Расширьте границы облака, включив ВЗ. Теперь шаг 2 надо выполнить на узлах С2 и СЗ. Следующим в порядке соединения выбираем С2, так как его коэффициент фильтрации, 0,5, лучше, чем подразумеваемый коэффициент 1,0 для не фильтрованной таблицы СЗ. Теперь порядок соединения (В4. С5. С4, А2. ВЗ. С2). Расширьте облако, включив С2. Новых узлов под облаком не появилось, поэтому шаг 2 выполняется только для узла СЗ. Теперь порядок соединения будет (В4. С5. С4. А2, ВЗ. С2. СЗ), и рис. 6.7 иллюстрирует текущее облако соединения. 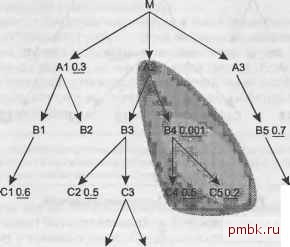 С6 0.9 0108 D2 Рис. 6.6. Облако уже соединенных таблиц, включающее четыре таблицы 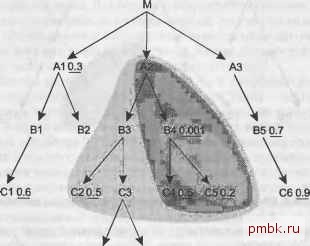 0108 02 Рис. 6.7. Облако уже соединенных таблиц, включающее семь таблиц Теперь для шага 2 у нас есть два новых узла под облаком соединения, D1 и D2, причем коэффициент фильтрации у D1 лучше. Так как к этим узлам никакие другие узлы снизу не присоединены, присоединим их последовательно в зависимости от коэффициентов фильтрации и перейдем к шагу 3, имея порядок соединения (В4. С5. С4. А2. ВЗ. С2. СЗ. D1. D2). Вся ветвь ниже А2 обработана и осталась только связь вверх к М (это главная таблица запроса), поэтому мы переходим к этому узлу. Так как мы достигли главной таблицы в корне дерева соединения, для оставшейся части задачи шаг 3 нам не понадобится. Применяйте шаг 2, пока не вставите в порядок соединения остальные таблицы. Сразу же под М (и под всем обла1Сом) находятся А1 и A3, причем фильтр есть только у А1, поэтому присоединяем таблицу А1. Теперь порядок соединения (В4. С5. С4. А2. 83. С2. СЗ. D1. D2. М. А1), а на рис. 6.8 показано текущее облако соединения. 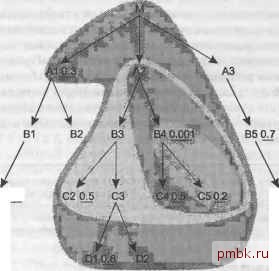 С10.6 С6 0.9 Рис. 6.8. Облако уже соединенных таблиц, включающее одиннадцать таблиц Сразу же под облаком находятся узлы В1, В2 и A3, но ни для одного из них нет фильтра, поэтому проверим фильтры следующего шага. Такие фильтры можно найти для С1 и В5, но фильтр С1 лучше, поэтому добавляем В1 и С1 к текущему порядку соединения. Теперь порядок соединения (В4. С5. С4. А2. ВЗ, С2. СЗ, D1. D2. М, А1, В1. С1). Все так же у нас нет лучшего выбора, чем оставшийся фильтр следующего шага для В5, поэтому присоединяем A3 и В5 в указанном порядке. Теперь осталось только два узла, В2 и С6, и оба можно сразу же присоединить, так как они напрямую присоединены к облаку. Выберем С6 первым, так как его коэффициент фильтрации равен 0,9, и это значение лучше, чем подразумеваемый коэффициент 1,0 для не фильтрованного соединения с В2. Полный порядок соединения будет следующим - (В4. С5. С4. А2. ВЗ. С2. СЗ. D1, D2, М. А1. В1. С1. A3. 85. Сб. В2). Кроме порядка соединения правила указывают, что база данных должна обращаться к таблице 84 через индекс для его условий фильтрации, а ко всем ос- тальным таблицам база данных должна обращаться при помощи вложенных циклов по индексам по их ключам соединения. Эти индексные ключи соединения - первичные ключи для соединений вниз с С5, С4, ВЗ, С2, СЗ, D1, D2, А1, В1, С1, A3, В5, Сб и В2 и внещние ключи для А2 (указывающий на В4) и М (указывающий на А2). Все вместе, это полностью описывает единственный оптимальный план из 17!, то есть 355 687 428 096 ООО возможных порядков соединения и всех возможных методов соединения и индексов. Однако этот пример все же имеет два слабых места. В реальных запросах редко бывает так много фильтрованных узлов, поэтому маловероятно, что для соединения такого количества таблиц будет лишь один оптимальный порядок. Чаще всего вы будете находить целый набор одинаково хороших порядков соединения, как я продемонстрировал в предыдущем примере. Последняя часть порядка соединения не сильно влияет на время вьшолнения, если первая часть порядка составлена правильно и все таблицы обрабатываются через их ключи соединения. В этом примере, как только база данных достигнет узла М, и, возможно, А1 по правильному пути, путь к оставшимся таблицам повлияет на время вьшолнения лишь незначительно. В большинстве запросов даже меньшая доля таблиц действительно важна для порядка соединения, поэтому вы получите прекрасный план, лишь правильно выбрав ведущую таблицу и выполняя для остальных таблиц вложенные циклы по ключам соединения в любом порядке, допустимом в дереве. ПРИМЕЧАНИЕ Если вам все равно нужно изменить запрос и есть шанс получить правильный порядок соединения полностью, сделайте это. Однако если у вас уже есть правильный план для начала порядка соеданения, улучшения могут не стоить беспокойства и работы по изменению запроса только для того, чтобы исправить порядок соединения. Особый случай обычно выполнение шагов процесса настройки без отклонений показывает себя превосходно, но проблема, показанная на рис. 6.4, может заставить применить последний трюк, особенно подходящий для Oracle. ПРИМЕЧАНИЕ- В этом разделе сначала описан особенно эффективный трюк, который иногда срабатывает в Oracle. Однако если вам нужно что-то подобное для других серверов баз данных, потерпите - в конце раздела я опишу менее эффективный вариант этого фокуса для других баз данных. Решение для Oracle Вернитесь к рис. 6.4 и представьте, что все таблицы кроме М относительно невелики и хорошо кэшированы, а М - очень большая и поэтому плохо кэширована, и доступ к ней существенно дороже, чем к остальным таблицам. Кроме того, М - это особенная таблица комбинаций, выражающая отношение многие ко многим меж-
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |