
|
|
Программирование >> Полное сканирование таблицы
пользуя соединение хэшированием, но сейчас я хочу сфокусироваться на том, чтобы научить вас мастерству оптимизации для наилучшего надежного плана. Мы уже нашли 12 наилучших порядков соединения, и мне необходим один из них для дальнейшего рассмотрения и завершения решения этой задачи. Я выбираю порядок соединения (С. 0. ОТ. 0D. ODT. Р. S. А). Окончательное решение для 8-стороннего соединения Чтобы закончить решение нашей задачи, нужно применить правила для надежных планов и получить желаемый порядок соединения в надежном плане. Надежный план применяет вложенные циклы по индексам, начиная с фильтрующего индекса для ведущей таблицы и затем следуя по индексам для ключей соединения. Далее наилучший план расписан в деталях (исходный запрос и условия фильтрации вы можете найти в главе 5). 1. Перейти к таблице Customers, используя индекс по (Last Name. First Name), каким-либо образом модифицировав запрос, чтобы этот индекс был доступным и полностью пригодным. 2. Соединить, применяя вложенные циклы, с таблицей Orders, используя индекс по внешнему ключу Customer ID. 3. Соединить, применяя вложенные циклы, с Code Transl ati ons (ОТ), используя его индекс по первичному ключу (Code Type. Code). 4. Соединить, применяя вложенные циклы, с Order Detai 1 s, используя индекс по внешнему ключу Order ID. 5. Соединить, применяя вложенные циклы, с Code Translations (ODT), используя его индекс по первичному ключу (Code Type. Code). 6. Внешнее соединение с применением вложенных циклов с Products, используя его индекс по первичному ключу Product ID. 7. Внешнее соединение с применением вложенных циклов с Shi pments, используя его индекс по первичному ключу Shipment ID. 8. Внешнее соединение с применением вложенных циклов с Addresses, используя его индекс по первичному ключу Address ID. 9. Если необходимо, сортировка полученных результатов. Любой план выполнения, не следующий этому порядку соединения, не использующий вложенные циклы или не использующий указанные индексы, не будет оптимальным надежным планом. Правильный выбор ведущей таблицы и индекса - это ключевая проблема в 90 % случаев, и этот пример не будет исключением. Первое препятствие при получении правильного плана - это проблема получения доступа к правильному ведущему фильтрующему индексу на первом шаге. В Oracle можно использовать функциональный индекс по значениям столбцов Last Name и Fi rst Name в верхнем регистре, чтобы при переходе к индексу не было сложных выражений. В других базах данных вы можете увидеть, что имена всегда хранятся (или должны храниться) в верхнем регистре, или вы можете денормали-зовать структуру новыми индексированными столбцами, которые повторяют имена в верхнем регистре, или же изменить приложение так, чтобы поиск зависел от регис- тра. Есть несколько путей решения данной специфичной проблемы, но вам придется правильно выбрать ведущую таблицу, чтобы хотя бы обнаружить такую проблему. Теперь, когда вы можете правильно выбрать и обратиться к ведущей таблице, все ли проблемы решены? Практически всегда у вас есть индексы по необходимым первичным ключам, но хорошо разработанная база данных не гарантирует (или не должна гарантировать), что у каждого внешнего ключа также есть индекс, поэтому следующая вероятная задача - убедиться, что существуют индексы по внешним ключам Orders(Custorier ID) и Order Details(Order ID). Они позволяют использовать необходимые для надежного плана, начинающегося с Customers, соединения вверх методом вложенных циклов. Другая возможная проблема заключается в том, что оптимизаторы для одной или нескольких таблиц могут выбрать метод соединения, отличный от вложенных циклов, и вам понадобится использовать подсказки или другие техники запрещения всех методов соединения, кроме вложенных циклов. Если сервер будет использовать этот сценарий, оптимизаторы, вероятно, также выберут другой метод доступа к таблицам, которые не соединяются вложенными циклами, получая все соединяемые строки за раз. ПРИМЕЧАНИЕ- Далее я покажу, что соединения сортировкой слиянием или хэшированием для такой небольшой таб-лиш>1 как Cocle Translatlons будут прекрасно работать, даже немного быстрее и без потери надежности, так как эти таблиш>1 не должны сильно разрастаться. В этом простом случае, если используются только указанные фильтры, порядок соединения может быть наименьшей из проблем, если вы правильно выберете ведущую таблицу и создадите все необходимые индексы по внешним ключам. Сложное 17-стороннее соединение На рис. 6.4 я намеренно привожу сложный пример, чтобы полностью продемонстрировать используемый метод. Я отбросил коэффициенты соединений, превратив рис. 6.4 в частично упрощенную диаграмму запроса, так как они не влияют на правила, которые я сформулировал. Решение этой задачи я объясню очень подробно, но, возможно, вы захотите сначала попытаться решить ее самостоятельно, чтобы проверить, какие части метода вы уже полностью понимаете. Для шага 1 быстро находим, что у В4 наилучший коэффициент фильтрации, равный 0,001, поэтому выбираем эту таблицу ведущей. Такой селективный фильтр лучше использовать вместе с индексом, поэтому в реальной задаче, если бы это был достаточно важный запрос, можно было бы создать новый индекс, чтобы использовать его для обработки 84. Но сейчас мы будем заниматься только порядком соединения. Шаг 2 говорит, что далее следует проверить присоединенные снизу узлы С4 и С5, отдавая предпочтение соединению с узлами с лучшей фильтрацией. Коэффициент фильтрации для С5 равен 0,2, а для С4 - 0,5, поэтому далее мы будем проводить соединение с С5. На данный момент порядок соединения (84, С5), и облако вокруг уже соединенных таблиц выглядит как на рис. 6.5. Если к С5 снизу были бы присоединены один или несколько узлов, теперь их следовало бы сравнить с С4, но так как внизу узлов нет, шаг 2 предлагает нам единственный выбор - С4. Расширив границы облака, чтобы захватить С4, мы видим, что под ним больше нет узлов, поэтому переходим к шагу 3, находим единствен- ный узел А2, присоединяющийся к облаку сверху, и добавляем его в строящийся порядок соединения, который теперь выглядит как (В4. С5. С4. А2). Облако вокруг уже соединенных таблиц выглядит как на рис. 6.6. 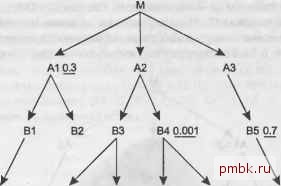 С10.6 С2 0.5 СЗ С40.5 С5 0.2 С8 0.9 DlOe D2 Рис. 6.4. Сложное 17-стороннее соединение 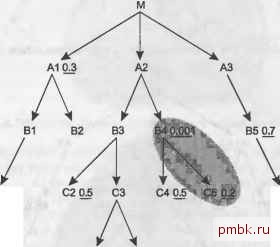 010.6 06 0.9 0108 D2 Рис. 6.5. Облако уже соединенных таблиц, включающее две таблицы Обратите внимание, что я закрасил исходное облако с двумя узлами другим оттенком серого. На практике вам не нужно стирать предыдущие облака, просто изображайте новые облака вокруг старых. Возвращаясь к шагу 2, найдем ниже текущего облака соединенных таблиц единственный узел, 83, и поместим его следующим в по-
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |