
|
|
Программирование >> Полное сканирование таблицы
щая вниз, на них, стрелка, связывающая их с детальным узлом наверху, но любой узел может находиться на верхнем конце любого количества указывающих вниз стрелок. Для всех соединений есть указывающие вниз стрелки. Внещние соединения не фильтруются, стрелки для них направлены вниз, внещние соединения могут быть только под внешними соединениями. Вопрос, на который отвечает запрос, - это обычно вопрос о сущности, представленной в корневом узле дерева (или об агрегациях этой сущности). Прочие таблицы просто предоставляют справочные и детализированные данные, хранящиеся в них для нормализации. Упрощенные диаграммы запросов Вы увидите, что множество подробностей, присутствующих на полных диаграммах запросов, не обязательны, разве что для самых редких проблем. Когда вы концентрируетесь на необходимых элементах, то вам нужен только скелет диаграммы и приблизительные коэффициенты фильтрации. Изредка требуются коэффициенты соединений, но обычно только когда любой из детальных коэффициентов соединения меньше 1,5 или главный коэффициент соединения меньше 0,9. Если только у вас нет причины подозревать, что вы встретились именно с этими редкими значениями для отношения главной и детальной таблиц, можете даже не беспокоиться о вычислении этих значений. Это, в свою очередь, значит, что меньшее количество данных требует создания более простых диаграмм соединения. Вам не потребуется узнавать количество строк для таблиц без фильтров. На практике в многосторонних соединениях обычно есть фильтры только для 3-5 таблиц, поэтому даже самый сложный запрос лепот изобразить на диаграмме, не используя множество запросов для сбора статистики. Отбросив ненужные детали, которые я только что перечислил, вы можете упростить рис. 5.5 до рис. 5.7. 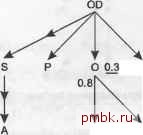 С 0.0002 ОТ Рис. 5.7. Упрощенная диаграмма запроса для рис. 5.5 Обратите внимание, что детальный коэффициент соединения от С к О на рис. 5.5 меньше 1,5, поэтому я продолжаю указывать его даже на упрощенной диаграмме на рис. 5.7. Когда дело доходит до фильтров, даже приблизительные значения обычно не нужны, если вы знаете, какой фильтр лучше и если другие конкурирующие фильтры не относятся к тому же родительскому детальному узлу. В нашем случае можно обозначить наилучший фильтр заглавной буквой F и малые фильтры - строчной буквой f. Рисунок 5.7 упрощается до рис. 5.8. 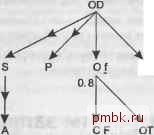 Рис. 5.8. Полностью упрощенная диаграмма запроса для рис. 5.7 Обратите внимание, что детальный коэффициент соединения от С к О меньще 1,5, поэтому я продолжаю указывать его даже на полностью упрощенной диаграмме на рис. 5.8. Хотя я удалил коэффициенты фильтрации с рис. 5.8, следует продолжать рисовать символ звездочки рядом с любыми уникальными фильтрами (фильтрами, гарантированно возвращающими не более одной строки). Также следует указывать фактические значения фильтрации для малых фильтров, относящихся к одному и тому же родительскому детальному узлу. Например, если у вас есть малые фильтры в узлах В и С на рис 5.9, укажите для них реальные коэффициенты фильтрации, как показано на рисунке, поскольку у них есть общий родительский детальный узел А.  В0.2 С0.9 Рис 5.9. Полностью упрощенная диаграмма запроса с коэффициентами фильтрации для общего предка На праетике вы обычно можете начать с упрощенной диаграммы запроса и затем по необходимости добавлять детали. Если план исполнения (о том, как его найти, я расскажу в главе 6), найденный из этой упрощенной задачи, выполняется настолько быстро, что дальнейшие улучшения бессмысленны, то работу можно считать законченной. Вы можете удивиться, узнав, как часто это случается. Например, пакетный запрос, который выполняется за несколько секунд несколько раз в день, достаточно быстр, чтобы его дальнейшее улучшение не требовалось. Схожим образом не нужно продолжать настройку любого оперативного запроса, который выполняется за 100 миллисекунд и который конечные пользователи совместно выполняют меньше 1000 раз в день. Если после первого раунда настройки вы считаете, что дальнейшая работа будет стоить приложенных усилий, то можете быстро проверить, осуществима ли дальнейшая настройка, посмотрев, не пропустили ли вы важные коэффициенты соединения. Самый быстрый способ сделать это - спросить, действительно ли единственный наилучший фильтр ответствен за практически все уменьшения количества возвращенных строк по сравнению с полностью не отфильтрованным запросом к самой детализированной таблице. Предполагая, что диаграмма соединения выглядит как перевернутое дерево, можно ожидать, что весь запрос, без фильтров, вернет то же количество строк, что и самая детализированная таблица в корне дерева соединения (то есть наверху). В случае с фильтрами вы ожидаете, что каждый фильтр сокращает количество строк, возвращенных из самой детализированной таблицы (в корне дерева соединения) на коэффициент фильтрации. Если произведение наилучшего коэффициента фильтрации на количество строк самой детализированной таблицы приблизительно равно количеству строк, которое возвращает весь запрос, то можете быть уверены, что не пропустили важных фильтров, и упрощенной диаграммы хватит. С другой стороны, если произведение количества строк самой детализированной таблицы на наилучший фильтр (или то, что вы считали наилучшим фильтром) намного превосходит количество строк, которое возвращает запрос, то, возможно, вы пропустили важную причину сокращения количества строк и необходимо собрать больше статистики. Если произведение всех коэффициентов фильтрации (подсчитанное или угаданное), умноженное на количество строк самой детализированной таблицы, даже близко не дает количества строк, возвращенного всем запросом, следует подозревать, что вам нужно больше информации. В частности, у вас могут быть скрытые фильтры соединений, коэффициенты соединений для которых неожиданно оказываются намного меньшими 1,0. Поиск таких фильтров и использование их для получения лучшего плана может обеспечить большую дальнейшую прибыль. Упражнения 1, Создайте диаграмму для следующего запроса: SELECT ... FROM Customers С. ZIP Codes Z. ZIP Demographics D. Regions R WHERE C.ZIP Code - Z.ZIP Code AND Z.Demographic ID - D.DemographicJD AND Z.Region ID - R.Region ID AND C.ActiveJlag - Y AND C.ProfiledJIag - N AND R.Name - SOUTHWEST AND D.Name IN (YUPPIE. OLDMONEY): Сделайте обычные предположения об именах первичных ключей, кроме первичного ключа ZIP Codes, который является таблицей ZIP Codes. Обратите внимание, что столбцы Name в REGIONS и ZIP Demographics имеют уникальные индек-
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |