
|
|
Программирование >> Полное сканирование таблицы
LEFT OUTER JOIN Departments D ON E.Department ID-D.Department ID: Эти запросы возвращают информацию обо всех сотрудниках, в том числе информацию об отделах, где те работают. Однако если для сотрудника нет соответствующего отдела, запрос все же возвращает данные сотрудника, причем в результирующих данных такие поля с ненайденными значениями, как D.Department Name, заполняются значениями null. С точки зрения настройки главным результатом внещнего соединения является то, что оно запрещает путь выполнения, который на основе данных из подчиненной таблицы пытается получить записи основной таблицы. В нашем примере база данных не может начать с таблицы Departments и искать соответствующие строки в таблице Employees, так как базе данных нужны данные обо всех сотрудниках, а не только о тех, для которых указан отдел. Позже я покажу, что это ограничение порядка соединения во внешних соединениях не всегда имеет большое значение, поскольку чаще всего нет необходимости проводить соединение в запрещенном порядке. Способы обработки соединений Типы соединений определяют, какие результаты необходимы запросу, но не указывают, как база данных должна выполнять эти запросы. Во время настройки SQL-запроса вы обычно просто знаете, какой именно результат запроса вы хотите получить, но вам необходимо также контролировать метод выполнения, чтобы добиться хорошей производительности. Чтобы правильно выбрать метод выполнения, необходимо понять, как они работают. Соединения при помощи вложенных циклов Самый простой способ эффективного вьшолнения соединения двух и более таблиц - это соединение при помощи вложенных циклов, показанное на рис. 2.7. Ведущвя таблице Первая твблица, с которой производится соединенив Вторая таблица, с которой производится соединение 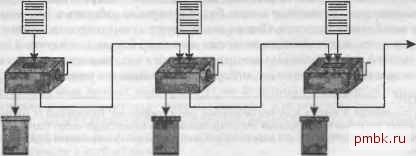 Рис. 2.7. Соединения методом вложенных циклов Выполнение запроса начинается с того, что можно считать однотабличный запросом к ведущей таблице (таблице, которую база данных считывает первой). При этом используются только условия, относящиеся исключительно к этой таблице. Считайте самый левый ящик с рукояткой на рис. 2.7 машиной для выполнения этого однотабличного запроса. Он отделяет неинтересные строки (которые направляются в мусорное ведро в левом нижнем углу) от интересующих нас строк (удовлетворяющих условиям однотабличного запроса) основной таблицы. Так как весь запрос является соединением, база данных не останавливается на достигнутом. Она передает результирующие строки из первого ящика в следующий. Задача второго ящика - по одной принимать строки из первой коробки, находить соответствующие строки в первой присоединяемой таблице, отбрасывать строки, не удовлетворяющие условиям запроса для уже рассмотренных таблиц, и передавать подходящие строки, для которых условия выполняются, дальще. Обычно база данных выполняет этот шаг соединения методом вложенных циклов путем индексного поиска по ключу соединения, который повторяется для каждой строки ведущей таблицы. Если соединение является внутренним, база данных отбрасывает строки, для которых на первом шаге не были найдены соответствия из присоединенной таблицы. Если же соединение внешнее, то база данных заполняет для таких строк места, предназначенные для значений из присоединенной таблицы, значениями null, если не может найти реальных существующих значений, сохраняя, таким образом, все строки из первого шага. Этот процесс продолжается в остальных ящиках, точно также присоединяя все остальные таблицы, пока запрос не будет завершен. В результате мы получаем полностью соединенные данные, удовлетворяющие всем условиям и соединениям запроса. На внутреннем уровне база данных выполняет этот план выполнения как вложенную группу циклов - внешний считывает строки ведущей таблицы, следующий находит соответствуюшие строки из первой присоединенной таблицы и так далее - поэтому такой способ и называется соединениемл<ешоЭол вложенныхцик-лов. В каждой точке процесс должен знать только то, где он в данный момент находится, и содержимое единственной результирующей строки, которую он создает. Поэтому для вьшолнения процесса требуется немного памяти и совсем не требуется места на диске. Вот почему планы с вложенными циклами такие надежные. Они могут создавать огромные результирующие наборы из больших таблиц, и при этом не будет заканчиваться память или пространство на диске, хотя вам придется ждать получения результатов довольно долго. Если вы выберете правильный порядок соединения, вложенные циклы будут прекрасно работать в большинстве важных для бизнеса запросов. Они демонстрируют лучшую производительность среди всех методов соединения или же они настолько близки к наилучшей производительности, что дополнительное преимущество в виде надежности этого метода заставляет выбрать именно его, игнорируя небольшие его недостатки. ПРИМЕЧАНИЕ- Говоря о надежности, я имею в виду исключительно метод соединения. Независимо от соединения, запросу может потребоваться объемный отсортированный результирующий набор (например, если присутствует фраза ORDER BY), для получения которого необходимо много памяти и дискового пространства. Соединения хэшированием Иногда база данных должна обратиться к соединяемым таблицам по отдельности, а затем соединить соответствующие строки и отбросить ненужные. Можно сделать это двумя способами: соединением хэшированием, которое рассматривается в этом разделе, и соединением с сортировкой слиянием, которому посвящен следующий раздел. На рис. 2.8 показано соединение хэшированием. Небольшой набор строк Просмотр с хэшированием Основной набор строк 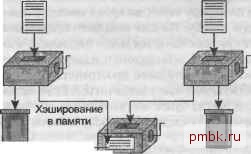 -►Соединенные строки Обычно в памяти Рис. 2.8. Соединение хэшированием На рис. 2.8 оба верхних ящика с рукоятками работают как независимо оптимизированные однотабличные запросы. На основе статистики по таблице и индексу стоимостной оптимизатор устанавливает, какая из двух независимых таблиц вернет меньше строк после фильтрации. Он выбирает хэширование всего результата запроса для этой таблицы. Другими словами, он выполняет некоторую рандоми-зирующую математическую функцию на ключе соединения и использует результат функции при выборе места для каждой строки в области хэширования. Идеальный алгоритм хэширования равномерно распределяет строки между некоторым количеством областей хэширования, приблизительно равным количеству строк. Так как области хэширования предназначены для небольшого результирующего набора, можно надеяться, что все они разместятся в памяти, но, если необходимо, база данных выделяет временное пространство на диске для размещения этих областей. Затем она выполняет большой запрос (верхний правый ящик на рис. 2.8), который возвращает ведущий набор строк. По мере того как каждая строка проходит этот шаг, база данных выполняет ту же функцию хэширования на ее ключе соединения и использует полученный результат для перехода прямо в соответствующую область хэширования другого набора строк. Попав в подходящую область хэширования, база данных производит поиск соответствующей строки в небольшом списке в этой области. Обратите внимания, что соответствие может быть и не найдено. Когда база данных находит соответствие (на рисунке это показано ящиком внизу в середине), Синтаксический оптимизатор Oracle никогда не выберет слияние хэшированием, но стоимостной оптимизатор часто делает это. Другае поставщики баз данных не используют синтаксические оптимизаторы.
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |