
|
|
Программирование >> Sql: полное руководство
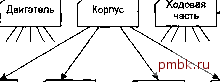
Программа для обновления данных о служащих Профамма для создания отчетов о служащих Профамма для начисления зарплаты ОСД 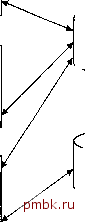 Главный файл сданными о служащих Файл учета раббчего времени Рис. 4ЛУЩтожение для начисления зарплаты, ; файлами Иерархические базы данных Одной из наиболее важных сфер применения первых СУБД было планирование производства в компаниях, занимающихся выпуском продукции Например, если автомобильная компания хотела выпустить 10000 машин одной модели и 5000 машин другой модели, ей необходимо было знать, сколько деталей следует заказать у своих поставщиков. Чтобы ответить на этот вопрос, необходимо выяснить, из каких частей состоит изделие, затем определить, из каких деталей состоят эти части и т.д. Например, машина состоит из двигателя, корпуса и ходовой части; двигатель состоит из клапанов, цилиндров, свеч и т.д. Список составных частей изделия по своей природе является иерархической структурой. Для хранения данных, имеющих такую структуру, была разработана иерархическая модель данных, которую иллюстрирует рис. 4.2. В этой модели каждая запись базы данных представляла конкретную деталь. Между записями существовали отношения предок/потомок, связывающие каждую часть с деталями, входящими в нее. Получая доступ к информации, содержащейся в базе данных, программа могла найти конкретную деталь (левую дверь) по ее номеру; перейти вниз к первому потомку (ручка двери); перейти вверх к предку (корпус); перейти в сторону к другому потомку (правая дверь).
 Записи Левая дверь 1 Ручка Правая дверь Днище Крыша 7TV /7
Рис. 40№ipopxH$CKaHjffa3a яанмбх,-содвржащаЛнформаиик) о ciSbiba0Sxчастях Таким образом, для выборки информации из иерархической базы данных требовалось перемещаться по записям, за один раз переходя на одну запись вверх, вниз или в сторону. Одной из наиболее популярных иерархических СУБД была Information Management System (IMS) компании IBM, появившаяся в 1968 году. Ниже перечислены достоинства IMS и реализованной в ней иерархической модели. Простота модели. Принцип построения баз данных в IMS был легок для понимания. Иерархия базы данных напоминала структуру компании или генеалогическое дерево. Использование отношений предок/потомок. СУБД IMS позволяла легко представлять отношения предок/потомок, например: А является частью В или А принадлежит В . Быстродействие. В СУБД IMS отношения предок/потомок были реализованы в виде физических указателей из одной записи на другую, вследствие чего перемещение по базе данных происходило быстро. Поскольку структура данных в этой СУБД отличалась простотой, IMS могла размещать записи предков и потомков на диске рядом друг с другом, что позволяло свести к минимуму количество опе/ раций чтения-записи. -СУБД IMS все еще является одной из наиболее распространенных СУБД для мэйнфреймов компании IBM. Обладающая очень высокой производительностью, она идеально подходит для приложений, связанных с обработкой большого числа транзакций: управление банкоматами, проверка номеров кредитных карточек и т.п. Хотя за последнее десятилетие производительность реляционных баз данных на порядок возросла, столь же сильно увеличились и требования к производительности приложений указанного выше типа, поэтому роль СУБД IMS по-прежнему велика. Сетевые базы данных Если структура данных оказывалась сложнее, чем традиционная иерархия, простота организации иерархической базы данных становилась ее недостатком. Например, в базе данных для хранения заказов один заказ мог участвовать в трех различных отношениях предок/потомок, связывающих заказ с клиентом, разместившим его, со служащим, принявшим его, и с заказанным товаром, что иллюстрирует рис. 4.3. Такие структуры данных не соответствовали строгой иерархии IMS. Клиенты Acme Mfg. Служащие Товары Bill Adams Size 4 Widget №112963 Заказы Риа, 4.3*Мнественныв > В связи с этим для таких приложений, как обработка заказов, была разработана новая, сетевая модель данных. Она являлась улучшенной иерархической моделью, в которой одна запись могла участвовать в нескольких отношениях предок/потомок (рис. 4.4). В сетевой модели такие отношения назывались множествами. В 1971 году на конференции по языкам обработки данных (Conference on Data Systems Languages - CODASYL) был опубликован официальный стандарт сетевых баз данных, который известен как модель CODASYL. Компания IBM не стала разрабатывать собственную сетевую СУБД и вместо этого продолжала наращивать возможности IMS. Но в 70-х годах независимьге производители программного обеспечения реализовали сетевую модель в таких продуктах, как IDMS компании Cullinet, Total компании Cincom и СУБД Adabas, которые приобрели большую популярность. С точки зрения программиста, доступ к сетевой базе данных был очень похож на доступ к иерархической базе данных. Прикладная программа могла: найти конкретную запись предка по ключу (например, номер клиента); перейти к первому потомку в конкретном множестве (первый заказ, размешенный клиентом); перейти в сторону от одного потомка к другому в конкретном множестве (следующий заказ, сделанный этим же клиентом); перейти вверх от потомка к его предку в другом множестве (служащий, принявший заказ). И опять программисту приходилось искать информацию в базе данных, последовательно перебирая записи, однако указывая при этом не только направление, но и требуемое отношение.
|
||||||||||||||||||||
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |