
|
|
Программирование >> Проектирование баз данных
Наш опыт показывает, что для каждой операции LIKE оптимизатор предлагает полное сканирование таблицы (на случай, если значение начи-, нается метасимволом), а для любого равенства по полному индексному ключу - поиск при помоши индекса. Хеш-ключи Выше мы подробно рассмотрели индексы, имеющие структуру В*-дерева. Давайте остановимся на более специализированном способе поиска, в котором применяется не индекс, а хеш-ключ. В Oracle этот механизм часто называют хеш-кластером, так как хеш-ключи можно использовать только для табличных кластеров. Основная идея, на которой строится работа хеш-ключей, состоит в следующем. Когда пользователь выполняет вставку строки в любую таблицу кластера (или обновление в кластерном ключе), значение хеш-столбца в новой строке обрабатывается специальной функцией (хеш-функцией), возвращающей числовое значение. Это значение затем используется для физического размещения строки в таблице. В процессе поиска строки значение индексного столбца обрабатывается хеш-функцией, которая выдает хеш-значение, указывающее местоположение этой строки. Это позволяет за одну операцию чтения получить блок, который должен содержать данные. Если блок находится в кэше, то операция ввода-вывода вообще не выполнятся. Естественно, это более эффективно, чем индекс, имеющий структуру В*-дерева, который требует выборки как минимум одного индексного блока и одного блока данных и который может (в большой таблице) потребовать посещения четырех индексных блоков и одного блока данных (в сумме пять посещений блоков), а также, вероятно, трех операций ввода-вывода - при нормальной эффективности кэша. П/тмечапие Должны признаться, что мы использовали хеш-кластеры только в тестовых средах и никогда не сталкивались с живой системой, в которой применялось бы хеширование. Однако мы общались с людьми, получившими при использовании хеш-кластеров неутешительные результаты. По их словам, на загрузку хеш-кластеров, как и всех кластеров, уходит чертовски много времени. Свойства лет-ключей Давайте рассмотрим некоторые свойства хеш-ключей. Хеш-ключ можно применять только при поиске по равенству. Если хеш-ключ используется эффективно, то должна быть одна операция чтения на выборку. Для эффективной работы хеш-ключа необходимо точно задать размеры таблицы. Для эффективной работы хеш-ключа необходим хороший алгоритм хеширования. При заниженных размерах таблицы или плохом алгоритме приходится связывать несколько блоков в хеш-кластере, что влечет за собой выполнение дополнительных операций ввода-ввода как при выборке, так и при вставке. Завышение размеров таблицы приводит к появлению разреженных блоков и, следовательно, к неэффективному полному сканированию таблицы. Общий объем необходимого пространства в хеш-кластере с нормально установленными размерами должен быть меньше, чем сумма объемов данных и индексов, имеющих структуру В*-дерева. Вместо хеш-функции, которая предлагается в Oracle, можно написать свою. (В версиях начиная с 7.2 этот процесс проще, чем в предыдущих версиях.) Если столбец таблицы содержит целочисленные значения, имеющие равномерное распределение, его можно использовать в качестве хеш-ключа, не применяя никаких функций (с помощью HASH IS). Именно это позволяет задавать собственную хеш-функцию в версиях 7.0 и 7.1. Загрузка данных в хеш-кластеры всегда выполняется намного дольше, особенно по сравнению с таблицей, из которой индексы перед загрузкой удаляются, а после загрузки пересоздаются. Эту проблему помогает решить сортировка по хеш-ключу перед загрузкой. Хеш-ключи не следует использовать в случае, если ключ подвержен изменениям, так как при этом понадобится переставлять всю строку. Это, конечно, характерно для всех кластерных ключей. Хеш-ключи вряд ли стоит применять, если один и тот же ключ используется и для сканирования. Этот механизм не поддерживает сканирование, и, возможно, придется строить по этому же ключу обьпный индекс. Хеш-ключи нельзя объявлять уникальными. Это серьезный недостаток, потому что, если ключ уникален и пользователь хочет, чтобы Oracle обеспечила его уникальность, он должен либо применить ограничение UNIQUE или PRIMARY KEY (которое построит традиционный индекс), либо создать триггеры BEFORE INSERT и BEFOR UPDATE, проверяющие этот ключ. Чтобы основанное на триггерах решение работало надежно, а не просто большую часть времени, требуется эксклюзивная блокировка. Обычно она устанавливается на кластеризованной таблице, но - если это может вызвать серьезное снижение производительности - решение можно построить с помощью пакета DBMS LOCK (который есть в Oracle?) путем блокирования хешированного ключевого значения. Хотя при этом решении используется кооперативная блокировка, которую мы обычно не рекомендуем (из-за того, что какая-нибудь программа может отказаться от совместной работы) и при которой блокировка помещается в триггер, единственный путь избежать его - выполнять программу с отключенным триггером. Пример хеш-кластера Позже мы еще остановимся на некоторых затронутых нами проблемах, а сейчас давайте рассмотрим, как выглядит кластер. На рис. 6.6 иллюстрируется упрощенный пример хеширования. В этом примере у нас три основных блока. Поскольку в каждом блоке может располагаться в среднем всего четыре строки, а во второй блок хешируются пять строк, то имеется блок переполнения, содержащий одно значение - 135. Осуществляя поиск по ключу 135, Oracle применит алгоритм хеширования, который укажет, что строка находится в блоке два. Система прочитает блок два, просмотрит все находящиеся в нем строки, но нужного значения не обнаружит. Однако она отметит, что данный блок является связанным, прочитает следующий связанный блок и просмотрит его. Этот процесс будет продолжаться до тех пор, пока строка не будет найдена или пока не будет просмотрен последний связанный блок, но нужная строка обнаружена не будет. Хеш-ключ Блоки Oracle 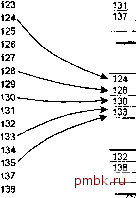 .135 Рис 6.6. Определение местонахождения строки с помощью хеш-ключей Как мы говорили ранее, хеш-ключи можно использовать только для поиска по полностью заданному ключу (который может состоять более чем из одного столбца). Для поиска в диапазоне, поиска неэквисоединений и частичных совпадений с ключом их применять нельзя. Впрочем, ничто не мешает вам построить индекс, имеющий структуру В*-дерева, для хеш-столбца и сделать возможными и эти методы поиска. Но поскольку в плане производительности хеш-поиск не намного лучше поиска по индексу (по крайней мере, по нашим наблюдениям), использование комбинаций хеша и В*-дерева для одного и того же столбца (столбцов) не дает ощутимой выгоды. Единственный случай, когда превосходство хеш-поиска над поиском по обычному индексу весьма существенно, - использование функции HASH IS.
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |