
|
|
Программирование >> Проектирование баз данных
вариантом является хеш-ключ, особенно если нет фамилий, которые встречаются больше нескольких раз. Естественно, для фамилий служащих это вряд ли возможно. Предположим, что не всегда в запросе выполняется сравнение на равенство (как в нашем примере) и нам приходится выдавать запросы, например, такого вида: SELECT emp.empno , emp.sal FROM employees emp WHERE emp.ename LIKE SM%; В этом случае мы, вероятно, выбрали бы индекс, имеющий структуру В*-дерева, или полное сканирование таблицы. По мере того как искомое выражение будет сокращаться до S% , полное сканирование таблицы будет выглядеть более приемлемым. Оптимизатор по стоимости в версии 7.3 сумеет выполнить оптимизацию правильно, но проектировщику следует помнить о проблеме связанной переменной, которую мы рассматриваем в разделе Проблема связанной переменной этой главы. Почему бы не индексировать все? Почему бы не индексировать в таблице каждый столбец, по которому] возможен поиск? В ответ на это сразу же хочется возразить следующее: 1. Если существует несколько неуникальных индексов, которые можно использовать, то у оптимизатора по правилам нет приемлемого алгоритма выбора одного из них. У оптимизатора по стоимости такой алгоритм есть, но в версиях до 7.3 оценивается только избирательность индекса, а не значение ключа.* При.тсчшше Oracle-наркоманы тратят впустую массу машинного времени, пытаясь определить, какой индекс выберет оптимизатор. Если вас интересует ответ на этот вопрос, то он звучит так: первый, который найдет . Конечно же, этот ответ совершенно бесполезен, потому что определить, какой индекс оптимизатор найдет первым, очень трудно. Оптимизатор очень плохо определяет, какие неуникальные индексы могут замедлить запрос в тех или иных случаях, особенно для столбцов, которые не очень избирательны (т.е. спектр значений в них не очень велик). 2. Чем больше индексов, тем выше затраты на их сопровождение при обработке DML-операторов. Общее эмпирическое правило гласит: если работу по вставке строки в таблицу принять за единицу, то для создания Это намеренное упрощение индексной статистики, применяемой в версиях с 7.0 по 7.2. Данный алгоритм учитывает как число отдельных значений, так и фактор их кластеризации. (Однако нужно ли вам это знать?) элемента индекса требуется три такие единицы. Следовательно, при вставке строки в таблицу с тремя индексами нужно выполнить в десять раз больше работы, чем при вставке строки в неиндексированную таблицу. Вот вам и пища для размышлений! 3 Индексы занимают ценное пространство базы данных, причем блоки-листья, которые обычно занимают свыше 90% индексного пространства, никогда не сжимаются. Кроме того, повторяющиеся ключи хранятся в количестве, равном числу экземпляров (за исключением кластерных индексов). Типы индексов и методы индексирования Сейчас мы более подробно рассмотрим некоторые связанные с индексами вопросы, которые были затронуты в предыдущих разделах. Индексы, имеющие структуру В*-дерева Индексы, имеющие структуру В*-дерева (сбалансированного дерева), - это традиционная форма индексов для баз данных Oracle. Изображение этой структуры напоминает перевернутое дерево (отсюда и название). Она состоит из корневого блока, блоков-ветвей и блоков-листьев. Реализация этой структуры индексов в Oracle имеет ряд интересных особенностей, включая оптимизацию, допускающую наличие действительно одноуровневых индексов, в которых корневой блок также является единственным блоком-листом. (Здесь аналогия с деревом несколько нарушается.) На рис. 6.4 изображен ивдекс, имеющий структуру В*-дерева, для примера из предыдущего раздела. Осуществляя поиск определенного ключевого значения, Oracle сначала читает корневой блок. Сравнивая значения в корневом блоке с искомым, Oracle определяет блок-ветвь для диапазона значений, в который входит искомое значение. Затем выполняются чтение блок-ветви и аналогичная операция по определению соответствующего блока-листа (или ветви следующего уровня - в зависимости от глубины индекса). Если нужный элемент находится в блоке-листе, то система выдает Идентификатор строки соответствующего элемента данных в блоке данных, к которому затем можно обратиться посредством одиночного посещения блока. Если блок еще не находится в буферном кэше Oracle, то для этого понадобится операция чтения с диска. <BR JO MAR 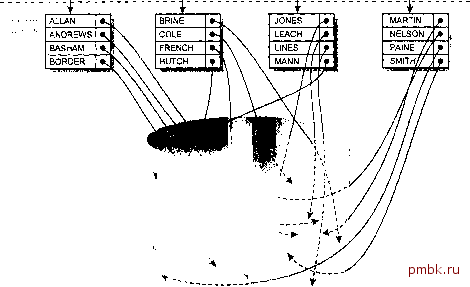 Puc. 6.4. Индекс, имеющий структуру В*-дерева Примечание Следует отметить два случая, когда после выборки идентификатора строки из индекса может понадобиться несколько посещений блока. Первый - если строка имеет в длину более одного блока (так называемая расщепленная строка), и второй - когда строка за время своего существования увеличилась и ее прищлось переместить из исходного блока в другой {мигрировавшая строка). В редких случаях строка может сначала мигрировать, а затем опять увеличиться и стать расщепленной. Рассмотрим некоторые свойства индексов, имеющих структуру В*-дерева. 1. Количество операций ввода-вывода, необходимых для получения идентификатора строки, зависит от числа уровней ветвления дерева. По мере того как индекс увеличивается в размерах, Oracle может добавлять в него новые уровни, чтобы обеспечить сбалансированность дерева. Однако в действительности практически невозможно получить более четырех уровней. Например, при двухкилобайтных блоках базы данных индекс для 1 со
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |