
|
|
Программирование >> Проектирование баз данных
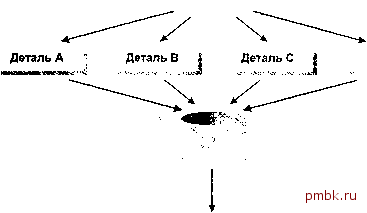 Деталь D Сводка Рис. 14.4. Пакетная обработка параллельными потоками с процессом подведения итогов Разбивка пакетного потока на параллельные процессы выгодна, когда имеется одна большая таблица, управляющая основным запросом. Разбивка может быть особенно эффективна, если в системе много центральных процессоров. Однако при ее использовании необходимо помнить следующее: Даже несмотря на то, что потоки можно организовать так, чтобы они обрабатывали разные сегменты данных, существует риск возникновения конкуренции за блокировку, например, в совместно используемой родительской строке с денормализованным столбцом, содержащим агрегированное значение. Если один из потоков столкнется с ошибкой и по какой-то причине откажет, то весь процесс придется считать потерпевшил! неудачу, несмотря на то, что некоторые другие процессы, возможно, завершились и закончили обработку. Если пакетный поток разбивается на параллельные процессы, необходимо соблюдать осторожность при восстановлении и перезапуске. В этом случае довольно трудно добиться равномерного распределения нагрузки между потоками. В примере разбивка осуществлялась для офисов и складов, но она может быть очень неравномерной. В следующем разделе предлагается метод решения этой проблемы, однако для его реализации необходимы значительные затраты на разработку. Повторим мысль, высказанную нами выше. Если распределить данные по нескольким дискам, к которым возможен одновременный доступ, то это увеличит скорость пакетной обработки независимо от того, какие ресурсы более важны для данной задачи: центрального процессора или системы ввода-вывода. Наша цель - задействовать как можно больше наличных ресурсов. Анализ ситуации: Oracle Payroll Как мы упоминали в главе 5, первая редакция продукта Oracle Payroll работала под Oracle версии 6. Чтобы обеспечить необходимую степень специализации и гибкости, в этом продукте использовались анонимные блоки динамического PL/SQL, которые выполняли подробные расчеты заработной платы. Сказать, что этот подход изначально вызвал проблемы с производительностью - значит, сказать очень мало! Бета-тестировшики сообшали, что для расчета заработной платы требовалось до десяти секунд на одного сотрудника. Исследования, проведенные группой, 1сурируюшей этот продукт, показали, что проблема отчасти состояла в синтаксическом анализе анонимных блоков PL/SQL. Они пришли к выводу, что эту проблему можно частично разрешить путем реализации большого кэша для курсоров. Тем не менее, было очевидно, что интерпретатор PL/SQL версии 1 при вьшолнении расчетов просто потребляет очень много ресурсов центрального процессора. Группа также отметила, что все заказчики бета-версии работали с аппаратными средствами Sequent, причем у каждого было минимум четыре процессора. Учитывая все это, было принято решение о параллельном выполнении процесса расчета. Группа исследовала разную тактшсу, но в конечном итоге остановилась на динамическом распределении. Предварительное распределение сотрудников по конкретным процессам не имело смысла по двум причинам. Во-первых, для разных сотрудников могли понадобиться очень разные объемы операций обработки; во-вторых, сушествовала реальная опасность того, что одному процессу будут назначены все трудные случаи и он завершится через несколько часов после других. Эти опасения можно понять, если подумать о различиях в расчетах заработной платы следующих категорий работников: клерка, который отработал стандартный месяц и не платит ни местный, ни государственный подоходный налог; продавца, структура комиссионных у которого на протяжении месяца изменялась, который платит и местный, и государственный налог и у которого старая и новая схемы комиссионных предусматривают разные ставки по разным категориям товаров с дополнительным вознаграждением за выполнение плановых показателей. Архитектура процесса, к которой в конечном итоге пришла вышеупомянутая группа, позволяла запускать любое число процессов расчета зарплаты. Каждый процесс производил вызов распределителя , который устанавливал эксклюзивную блокироввсу на таблице распределения, вьщелял этому процессу 20 сотрудников, затем регистрировал выделение, завершал работу и возвращал управление процессу расчета. После расчета зарплаты этих 20 сотрудников процесс вновь вызывал распределитель и продолжал так работать до тех пор, пока распределитель не сообщал, что больше сотрудников нет. На этом этапе процесс вставлял итоговые данные в базу данных и завершался. Естественно, процессы расчета зарплаты вполне могли столкнуться с конкуренцией на этапе распределения сотрудников, но такая блокировка обьпно действовала в течение всего 10% общего времени и конкуренция за эту блокировку была незначительной. Параллельный расчет заработной платы сразу же принес успешные результаты - производительность возросла на порядок. Но, к сожалению, была и ложка дегтя в бочке меда. Очень часто процесс расчета зарплаты неожиданно останавливался с весьма неприятным сообщением: ORA-00060 : deadlock detected while waiting for resource ( при ожидании ресурса обнаружена взаимная блокировка ) Распределитель тратил много времени на определение того, как случилось, что он выделил одного и того же сотрудника более чем одному процессу расчета. Через несколько недель в группе поняли, что эти взаимоблокировки вызваны внутренними проблемами Oracle. Нужно было лишь выдать ROLLBACK, несколько секунд подождать, а затем повторить попытку. Этот прием обработки взаимоблокировок был хорошо известен членам группы, но они не стали утруждать себя его реализацией, поскольку убедили себя, что взаимоблокировка не возникнет. Это все равно что ехать на мотоцикле без шлема, убедив себя в том, что в аварию вы не попадете! К сведению Взаимоблокировки такого типа встречаются очень редко и имеют место лишь в случае, когда несколько процессов пытаются одновременно осуществить блокировку на уровне строк в одном и том же блоке. Наступает момент, когда Oracle не хватает места, для того чтобы записывать, кому принадлежит блокировка, и СУБД ожидает, пока один из других процессов не выполнит фиксацию или откат транзакции. Если вам очень не повезет, система выберет процесс, который уже ожидает одну из ваших блокировок, в результате чего возникнет взаимоблокировка. Мы не говорим, что существует какой-то предел общего числа блокировок уровня строки (этот предел равен числу строк в распределенной базе данных). Мы говорим лишь, что существует ограничение на число разных процессов, которые могут одновременно удерживать блокировки в одном блоке. Это число зависит от объема свободного пространства в блоке и всегда больше или равно значению параметра INITRANS для данного объекта. Эта проблема редко, но встречается, поэтому мы рекомендуем учитьгеать взаимоблокировки на всех этапах проектирования программ.
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |