
|
|
Программирование >> Проектирование баз данных
Сценарий 3 Теперь наш вице-президент, реализуя свои властные полномочия, требует, чтобы обновления в столбец с заработной платой вносились только отделом кадров в Чикаго. Здесь можно использовать то же решение, что и в сценарии 2, и просто управлять привилегиями обновления с помошью триггеров на таблицах. Однако предположим, что наш требовательный вице-президент хочет выполнять просмотр и обновление из одной экранной формы, В этом случае мы можем для просмотра данных использовать представление, описанное в сценарии 1, но, конечно, обновлять данные через это представление будет нельзя. Поэтому придется включить в представление псевдостолбец, содержащий сведения о местоположении строки, и с помощью этих данных и динамического SQL генерировать соответствующее предложение UPDATE. Однако теперь мы обязаны выполнить двухфазную фиксацию. Теперь давайте рассмотрим новую модель данных, поскольку рассматриваемая до сих пор модель вряд ли может проиллюстрировать более сложное распределение данных по узлам. Вспомните, ранее мы говорили о том, что единственными причинами для распределения данных являются стремление сократить сетевую нагрузку или повысить готовность, а в этом примере вряд ли может идти речь о какой-либо из них. Наша новая модель показана на рис. 12,9, 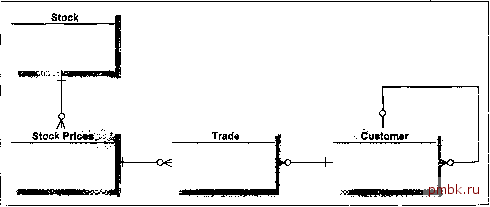 Рис. 12.9 Модель данных для более сложных распределенных сценариев Сценарий 4 в каждой стране торгуют в основном товарами, которые находятся на местном складе. Существуют и международные компании, действующие во всех трех странах. Они должны иметь возможность вызывать любой локальный офис и получать информацию о своем глобальном портфеле заказов по состоянию на предыдущий вечер (по местному времени). Давайте сначала рассмотрим сущность Customer ( Покупатель ). У нее имеется рефлексивное отношение ( свиное ухо ), показывающее, что покупатель может иметь материнскую компанию (Company). Более того, эта компания может находиться в другой стране. Необходимо иметь возможность соединять локального покупателя с удаленным. Однако это не критичная по времени операция, и можно спокойно жить, не выполняя немедленного обновления для нелокальных покупателей. Поскольку данные о покупателях распределены по узлам и ярко выраженный главный узел отсутствует, мы, скорее всего, остановимся на мультимастер-таблице, которая реплицируется асинхронно. Единственный конфликт, который нужно здесь учесть, возникает, когда один из пользователей связывает компанию с уже удаленной родительской таблицей из другой страны. Однако эта ситуация маловероятна. В этом сценарии каждый узел интересует только локальная информация о запасах (Stock) и ценах (Stock Price), поэтому для этих сущностей можно реализовать отдельные нераспределенные таблицы. С видами торговли (Trade), возможно, будет труднее, учитывая требование, что каждая страна должна предоставлять достаточно точную информацию, необходимую для оценки состояния всей международной корпорации. Лучший вариант для этих данных - реализовать сущность Trade как локальную таблицу и создать в таблице CUSTOMERS денормализованный столбец, содержащий текущее положение (он должен обновляться при каждой сделке). Вести этот столбец можно простым триггером. Если у покупателя есть материнская компания, должен срабатывать еще один триггер, обновляющий эту компанию. В этом случае конфликт более вероятен. Рекомендуем использовать аддитивный метод разрешения конфликтов. Сценарий 5 Этот сценарий похож на предыдущий, но здесь разрешена торговля товарами с иностранных складов. Поэтому при ведении торговли существенно важно знать курсы валют и использовать самую последнюю цену. Таблицы CUSTOMERS и TRADES могут оставаться в той же форме, что и в предыдущем примере, но поскольку цены товаров всегда должны быть полностью синхронизированы, у нас есть только один выбор: использовать для них синхронную симметричную репликацию. Однако если часть сети откажет, мы не сможем обновить цены ни в одной системе. Чтобы ослабить влияние этого фактора, придется либо покупать дополнительное оборудование, либо создать свою собственную форму синхронной симметричной репликации, которая при определенных управляемых условиях способна выдерживать системные отказы и откладывать синхронизацию. Еще один вариант - иметь всего одну копию данных, а деньги вложить в быстродействующую сеть! Использование распределенных баз данных для перехода в аварийный режим Некоторые организации стремятся оправдать реализацию распределенной структуры лишь тем, что она отличается устойчивостью к отказам и обеспечивает возможность работы при выходе из строя сервера. При внимательном проектировании этого, конечно, добиться можно. Если же это главное требование, то более дешевым (и более простым) выходом может быть приобретение дополнительного оборудования. Сушествует простое правило: если обязательным условием фиксации какой-либо транзакции является предварительное получение ответа от другой системы, то качество обслуживания в случае отказа сервера или соединения может снизиться. Ясно, что синхронные RPC и синхронная симметричная репликация, как и двухфазная фиксация предполагают получение ответа от сервера. Снимки и асинхронная симметричная репликация в этом отношении менее чувствительны, потому что обновления в этом случае всегда откладываются и при отказе могут быть отложены еще на некоторое время. Однако если используются обновляемые снимки и главный узел не работает, то наступает момент, когда снимки начинают отличаться и вероятность конфликта повышается. Один из авторов видел план аварийного сценария, по которому какой-либо из удаленных серверов принимает на себя ответственность за центральный узел (на котором находится большинство главных таблиц) в случае продолжительного отказа последнего. Взяв на себя роль центрального сервера, он продолжает обслуживать локальных пользователей. Это еще нужно попробовать на практике, и автор продолжает относиться к этому несколько скептически, поскольку эти серверы находятся друг от друга на расстоянии многих километров. Как всегда, мы искренне надеемся, что эта авария никогда не произойдет. Другие факторы, влияющие на проектирование в этом разделе описывается еще несколько факторов, влияющих на проектирование распределенных баз данных. Столбцы типа LONG Столбцы, определенные как LONG, вызывают при проектировании распределенных баз данных ряд проблем. Таблицы, которые содержат длинные столбцы, не могут реплицироваться и участвовать в двухфазной фиксации. Снимки также не могут включать столбцы типа LONG. Если разобраться, то это имеет большой смысл: разве мы хотим, чтобы сеть была забита
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0.001
При копировании материалов приветствуются ссылки. |