
|
|
Программирование >> Проектирование баз данных
потому что для запросов необходимо наличие только локальной копии. Производительность обработки запросов оптимальна, так как все запросы можно выполнять локально. Самый неприятный момент, связанный с этим методом, наступает, когда проектировщику приходится рещать, по какому пути пойти в случае недоступности одной или нескольких баз данных и что делать, если недоступна часть сети, В первой ситуации (недоступна одна или несколько баз данных), как правило, необходимо продолжать работу с теми серверами, которые выжили, при условии, что можно будет вернуть отсутствующие базы данных в строй, когда их готовность восстановится. Во второй ситуации (недоступна часть сети) необходимо установить ряд правил относительно того, каким подмножествам пользователей разрещается работать в случае отказов сети. Для обеспечения абсолютной надежности эти правила должны устанавливать, что если какое-то подмножество работает с разрешенным обновлением, то оно должно являться единственным работающим подмножеством. Более того, все остальные копии таблицы должны быть ресинхронизированы перед тем, как они станут доступны для использования. Сделать все это нелегко. Комбинирование и сопоставление методов Как мы уже говорили, необходимо рассмотреть каждую таблицу (или группу родственных таблиц) и выполнить для нее (или для них) фрагментационный анализ. Нужно решить, где в таблице должны быть расположены данные, чтобы оптимизировать и производительность, и готовность для тех пользователей, которым необходимо видеть эти данные и оперировать ими. Если в результате этого анализа принимается решение о том, что данные следует физически расположить на нескольких узлах, то нужно определить, как разбить или реплицировать данные между этими узлами. Сделав это, можно выбирать один из вариантов, которые мы предложили в этой главе (помня о шести -остях ). Конечно, метод, который хорош для одной таблицы, может не быть оптимальным для другой. Поэтому вполне допустимо решение, в котором (обоснованно) комбинируются разные технологии. Комбинация обновляемых и необновляемых снимков плюс набор удаленных вызовов процедур - вполне жизнеспособное решение. Обычно существовало ограничение, запрещавшее смешивать снимки и реплицированные таблицы в одной схеме базы данных. Как нам кажется, в версии 7,3 этого ограничения уже нет. Тем не менее рекомендуем всем, кто думает над использованием комбинированных методов, тщательно проанализировать степень сложности поддержки такой конфигурации и задачу ее администрирования. Кошмар адмгтистратора БД Распределенные базы данных, особенно новейшие их разновидности, ставят перед администратором БД интересные задачи - еще до того, как начинают происходить сбои в сети! Создание схем - задача, конечно, не из тривиальных, хотя ее и существенно облегчает утилита Replication Manager (часть Oracle Enterprise Manager в Oracle версии 7.3). Хотя Oracle Enterprise Manager поставляется со всеми платформами, он работает только под MS Windows NT. Без Replication Manager настройка средств репликации требует от администратора БД выполнения ряда процедур, большинство из которых имеют очень длинные имена, например: DMBS REPCAT AUTH . GRANT SURROGATE REPCAT ( REMOTESYS ) ; К тому же важное значение имеет порядок выполнения этих процедур. Более того, большинство CASE-продуктов не поддерживает определение распределенной схемы и генерируют DDL-операции, предполагающие, что все объекты будут определены в одной схеме. Для того чтобы добиться соответствия требованиям проектируемой распределенной системы, необходимо выполнить доводку вручную. Примерные сценарии Теперь, когда мы ознакомились с различными вариантами реализации распределенной базы данных, давайте рассмотрим, какие из них лучше использовать в определенньгк ситуациях. Для этого мы возьмем очень простые топологию сети и таблицу и с их помощью проиллюстрируем факторы, которые влияют на выбор технологии. Топология сети показана на рис. 12,7, а модель данных - на рис. 12.8, Для упрощения предположим, что на каждом узле работает один экземпляр базы данных, имя которого совпадает с именем узла. Лондон Гонконг Чикаго Рис. 12.7. Простая топология сети 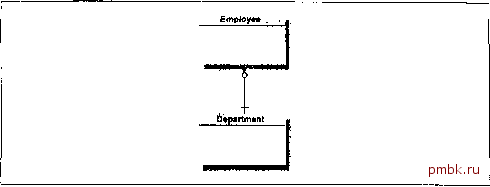 Рис. 12.8. Простая модель данных Сценарий 1 Филиалы организации работают автономно и не испытывают необходимости получать данные от других филиалов. Каждый узел отвечает за свои локальные данные о служащих и отделах. Но при этом пользователю в Чикаго нужно выдавать периодические отчеты, в которых применяются данные обо всех служащих организации. Этот сценарий прост, потому что программам составления сводных отчетов нужно лищь читать данные. В этом случае применяются удаленные запросы с каналами связи базы данных. В Чикаго необходимо создать два канала связи БД с Ловдоном и Гонконгом, создать представление, которое является объединением трех таблиц служащих, и запустить программу составления отчетов, работающую с этим представлением. Конечно, если такие отчеты составляются не очень часто, можно вообще не использовать распределенную базу данных, периодически получать из Лондона и Гонконга дампы таблиц (например, путем экспорта) и загружать их в Чикаго. Как однажды сказал один администратор БД, FedEx - самый лучщий сетевой транспортный уровень, который мы смогли найти для пересылки больпшх файлов. Сценарий 2 Наша организация приняла на работу нового вице-президента по кадрам, который заметил, что если местный начальник отдела кадров отсутствует (вероятно, играет в гольф), то все изменения в таблицах приходится откладывать до его возвращения. Вице-президент поставил задачу обеспечить возможность обновления из Чикаго таблиц служащих и отделов в отсутствие местного начальника отдела кадров. Этот сценарий также относительно прост, потому что обновление удаленных данных осуществляется отдельными транзакциями, в которых задействуется мало узлов. Используя канал связи БД, созданный для сценария 1, вице-президент может для удаленного сопровождения подключиться к удаленной системе, указав в конце строки соединения @hong kong или @london.
|
|
© 2006 - 2025 pmbk.ru. Генерация страницы: 0
При копировании материалов приветствуются ссылки. |